Hadoop Ecosystem Quick Start: 5 Key Components

By now we all know that Hadoop is a central part of many big data projects, but how do we integrate this technology with some of the more traditional approaches to data handling? Is there a way to make sure our Hadoop cluster is interacting with and enriching the rest of our analytics environment? Luckily, there’s a whole suite of utilities that interact with Hadoop to address these questions, and it’s important to know what they are and how to take advantage of them. In this article, we’re going to take a quick look at five commonly used utilities in the Hadoop Ecosystem to help you understand how they can be used to integrate the Hadoop framework with more traditional relational databases and leverage the data for analytical purposes.
What Is Hadoop?
To get started, let’s look at a simple definition of the tool that the utilities we’ll discuss support. Apache Hadoop is a framework that allows for the distributed processing of large data sets across clusters of commodity computers using simple programming model. It is an open-source data management system with scale-out storage and distributed processing. It’s designed with big data in mind and is ideal for large amounts of information. If you’d like some more in-depth details on Hadoop and its deployment, check out Susan Ma’s article from earlier this year.
The Hadoop Ecosystem
The Hadoop Ecosystem consists of tools for data analysis, moving large amounts of unstructured and structured data, data processing, querying data, storing data, and other similar data-oriented processes. These utilities each serve a unique purpose and are geared toward different tasks completed through or user roles interacting with Hadoop.
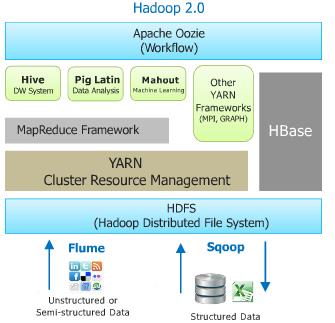
Some of the most common utilities used with Hadoop are the following five tools:
-
- HDFS
-
- Pig
-
- Hive
-
- Sqoop
- HBase

Let’s briefly go through these tools one by one without going into too much detail. Then, we can link all of them together to see how we can use the Hadoop Ecosystem with traditional databases.
HDFS: Hadoop Distributed File System
The Hadoop Distributed File System (HDFS) is a distributed file system designed to run on commodity hardware An HDFS instance may consist of hundreds or thousands of server machines, each storing part of the file system’s data.
Key HDFS Facts:
- HDFS has a master/slave architecture.
- The master is the high-end server while the slaves are commodity servers.
- Each commodity server stores each file or incoming piece of data as a sequence of blocks.
- All blocks in a file except the last block are of the same size. The blocks of a file are replicated for fault tolerance amongst the commodity servers.
- The block size and replication factor are configurable per file. An application can specify the number of replicas of a file. The replication factor can be specified at file creation time and can be changed later.
- By distributing storage and computation across many servers, the combined storage resource can grow linearly with demand while remaining economical at every storage level, large or small.
- HDFS is a scalable, fault-tolerant, distributed storage system that works closely with a wide variety of concurrent data access applications.
Pig
Pig is an open-source, high-level dataflow system that sits on top of the Hadoop framework and can read data from the HDFS for analysis.
Key Pig Facts:
- Pig process large volumes of data quickly and efficiently from the underlying HDFS.
- It provides a simple language for queries and data manipulation, Pig Latin, that is compiled in to map-reduce jobs that are run on Hadoop.
- Java knowledge is not required to learn Pig.
- Pig can work with the forms of data listed below:
- Structured data
- Semistructured data
- Unstructured data
- Pig is easy to learn and is similar to writing SQL, having built-in operations like JOIN, GROUP, FILTER, SORT, etc.
- It can read through a series of instructions and perform them.
- Companies like Yahoo, Microsoft, and Google use Pig to collect enormous quantities of data in the form of click streams, search logs, and web crawls.
- Because the data collected can be massive in size, it needs proper analysis to look for common industry trends.
Hive
Hive is a data warehousing package built on top of Hadoop that is used for complex data analysis and exploration.
Key Hive Facts:
- Hive is targeted toward users comfortable with writing SQL.
- It queries data using an SQL-based language called HiveQL.
- It was developed by Facebook and contributed to the Apache community.
- Facebook analyzed several terabytes of data using Hive.
Note: At this point, you might be thinking, “If we have Pig doing similar data analysis to Hive, then why do we need Hive anyway?” Well, there are some important distinctions between the two to consider:

The thing to remember is that Pig is used by researchers and programmers while Hive is used by analysts generating reports.
Sqoop: SQL-To-Hadoop
Apache Sqoop efficiently transfers bulk data between Apache Hadoop and structured data stores, such as relational databases. This allows stronger communication between traditional and big data-oriented data sources.
Key Sqoop Facts:
- Sqoop imports individual table or complete database to HDFS.
- Sqoop can also be used to extract data from Hadoop and export it into external structured data stores.
- Sqoop works with relational databases such as Teradata, Netezza, Oracle, MySQL, Postgres, and HSQLDB.
HBase
Apache HBase is a column-oriented, NoSQL database built on top of Hadoop.
Key HBase Facts:
- HBase stores data in key value pairs.
- HBase provides random access and strong consistency for large amounts of unstructured and semi-structured data in a schema-less database organized by column families.
- It puts data types traditionally excluded from standard RDBMS systems into an accessible, recognizable format.
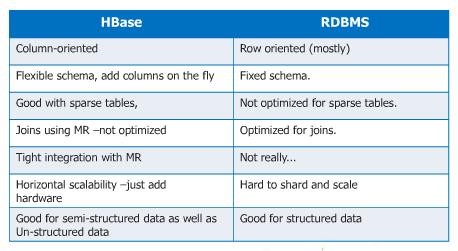
How HBase Differs from a Traditional RDBMS
Putting It All Together
Since we now have a brief overview of the common tools from the Hadoop Ecosystem under our belts, let’s try to connect the dots in a way that will let users on traditional databases leverage data coming from the Hadoop framework
Let’s say we have a huge XML file with unstructured data containing reviews for different products from website and we want to analyze the data. Since unstructured data is not handled in relational databases, we opt to use the Hadoop framework. To connect the Hadoop-based information to our analytics platform so it can be analyzed properly, we need to put it through a workflow that requires interacting with all the tools we’ve just discussed.
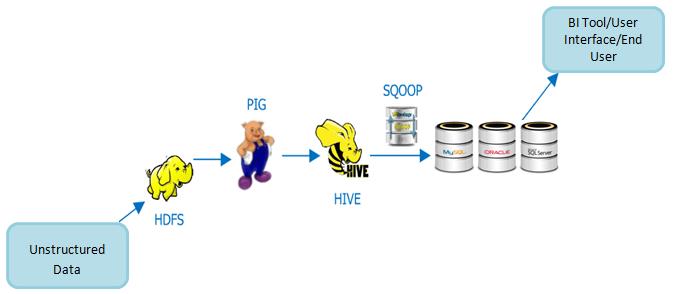
Workflow:
- The XML file is read into the HDFS.
- Map Reduce logic operations are performed to read the product categories and reviews to decide whether it’s good or bad review.
- The output data from step 2 is structured data
- PIG scripts are used on the output data to separate out different categories of products and reviews.
- HIVE is used write query to get top rated reviews per product category
- Output data from step 5 is read into the relational databases using Sqoop .
- Once we have data in the RDBMS we can leverage that data as per the requirements to get the top rated reviews for different product categories.
Conclusion
The scenario above is just one example of how you can combine Hadoop with relational data sources for analysis. If you’d like to get more information on Hadoop and other big data-related concepts, keep an eye out for future articles on the subject and take a look at the resources below:
- The Why, What, Who, and How of Successful Hadoop Deployment
- Do You Have a Big Data Problem?
- Diving into the Data Lake with Hadoop

Article References:
- edureka.co/big-data-and-hadoop
- hadoop.apache.org

