Diving into the Data Lake with Hadoop: The 5 Things You Need to Know

As we mentioned in a recent article, The Why, What, Who, and How of Successful Hadoop Deployment, there’s a lot you need to consider when implementing Hadoop to manage big data at your organization. Now we’ll build off that perspective and explore the data lake. Like any other new methodology just starting to gain ground in the information management space, there are a lot of assumptions about what data lakes can do and how they tie in with Hadoop-based infrastructures. In this article, we’ll discuss the most essential pieces of knowledge you need to wade into data lakes, dispel some of the rumors around them, and explain how they can fit into your information management ecosystem.
So what is a data lake, anyway? Well, put simply, it’s exactly what it sounds like: a big pool containing information from a bunch of different sources in a bunch of different formats with no particular hierarchy surrounding it. At first glance this seems like a really chaotic system, but when it’s set up and leveraged correctly it can be a huge asset.
The data lake format allows for a much higher degree of organic discovery than more rigid hierarchical structures and serves as a massive one-stop shop or staging ground for all your important information. It also preserves the original form of all data incorporated into it, letting you easily track changes and better understand the context/semantics at play in each source. This takes a lot more work in an environment where data goes through a lot of transformation, aggregation, and other forms of manipulation to make it more amenable to formal analysis since you have to backtrack through all these steps to verify its heritage.
On top of the quality benefits, a data lake is based on a concept called late binding, which builds a custom schema into every user query rather than forcing data into a single rigid schema like traditional transformation processes do. This allows for continual refinement of the data lake’s metadata stores and tags based on the contextual information from the analysis questions users are asking. The way the data is interpreted evolves over time, opening up more and more domain-specific analysis possibilities as new queries get designed.
No big modeling efforts, no dedication to a particular vendor or formatting standard, no doubt about where your data’s coming from or how it has been manipulated. Sounds great, right? Well, it can be, but there are several moving pieces you need in place to make data lakes really work for you. To help with this process, we’ve isolated the five facts we feel are most crucial for understanding how to take advantage of this powerful new information management strategy.
5. Related Terminology Is Critical
The data lake is part of a network of other concepts that need to be understood as a whole if you want to implement a successful repository of this type. You need to know the technologies that enable it, the information management philosophies that gave rise to it, and the different directions in which those building blocks have been taken.
The list of definitions below is designed as a starting point to help you focus your investigation on the right areas. With these terms under your belt, you’ll be prepared to learn the mechanics behind data lakes built on Hadoop and locate the resources required to put one in place at your organization.
Hadoop – Programming framework based in Java that supports large data set processing using a distributed computing environment. Hadoop makes it possible to efficiently run applications across systems that have thousands of nodes (objects) and terabytes of information stored in them through parallel processing and rapid data transfer rates between nodes. This approach also prevents system failure since tasks can transfer to any other node in the event that the one currently processing them goes down.
Object Storage – Approach for handling and manipulating multiple discrete units of storage called objects. These objects contain data but are not organized into hierarchies. Instead, they inhabit a flat address space (data lake) and are not placed inside one another. The system assigns each object a unique identifier that lets servers or end users retrieve objects without knowing exactly where they’re located. This allows for higher degrees of automation and streamlining, especially in the cloud.
Cluster – Group of servers and other resources that work together as a single system, enabling high availability, load balancing, and parallel processing.
Graph Database – Storage structure that provides index-free adjacency by using nodes, edges, and properties to represent and store data. Nodes represent individual objects in the database, edges represent the relationships between the different nodes, and properties are descriptive details about each node (for example, a node named “carrot” might have the property “vegetable”). This kind of storage makes the associations between large data sets more readily apparent and easier to process.
Resource Description Framework (RDF) – Family of specifications used as a general method for conceptually describing and modeling information implemented in web resources and knowledge management applications. RDF uses a variety of syntax notations and data serialization formats to create subject-predicate-object expressions called triples. The subject specifies the resource and the predicate specifies traits or aspects of that resource and expresses the relationship between the subject and the object. This is the protocol often used to organize graph databases and other object storage systems.
Semantic Query – Type of data retrieval expression (query) allowing for associative and contextual information gathering. These queries use pattern matching and digital reasoning to discover related objects and deliver precise results. They can infer answers from networks of data like the ones developed in Hadoop/included in data lakes. They’re also often used in natural language processing and artificial intelligence systems due to their ability to recognize recurring structures and make educated assumptions based on known formulas, such as a certain language’s grammar.
Open Data Platform (ODP) – Increasingly prevalent open-source Hadoop platform based on Apache Hadoop 2.6 and Apache Ambari. Hortonworks, IBM, Pivotal Software, GE, Infosys, SAS, EMC, Splunk, Teradata, and many others have all standardized their Hadoop distribution offerings to use this platform. Cloudera and MapR do not follow ODP and instead use their own Hadoop-based distribution structures.
Distributed Computing – Multiple computers working together from different remote locations to manage information processing or complete a computation problem. This is the model upon which Hadoop-based information management systems are built.
Master Data Management (MDM) – Technology-enabled discipline based around business and IT working together to ensure uniformity, accuracy, stewardship, semantic consistency, and accountability of their organization’s official shared master data assets. Master data itself is the set of uniform, consistent identifiers and extended attributes that describe all core entities of an enterprise, such as customers, prospects, citizens, suppliers, sites, hierarchies, and charts of accounts. Having an MDM strategy in place helps increase the efficiency of Hadoop and data lake projects.
4. There’s Still Room for Traditional Analytics Frameworks
Deciding to implement a data lake at your organization doesn’t mean that all your previous work with more traditional database/data warehouse configurations and analyses conducted on transformed data go out the window. In fact, a data lake can be an excellent way to augment those efforts and ensure the highest levels of quality and consistency across all your information management and business analytics resources.
The key to making a data lake function in this manner is viewing it both as a data repository in its own right and a data preparation layer feeding more structured data repositories. You can see this multifunctionality through the ways in which different information management-related roles and technologies within an organization access the data lake.
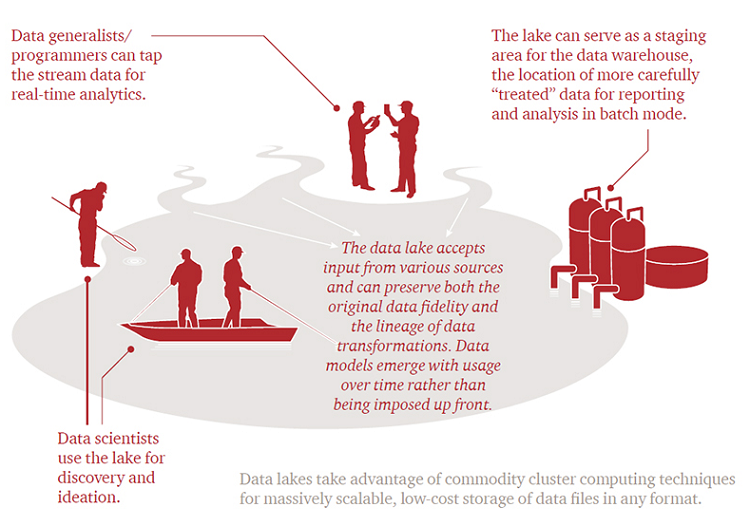
What is a data lake? Digital image. pwc. PricewaterhouseCoopers LLP. Web. 1 July 2015.
Once verified data flows into the data lake and starts having contextual metadata generated around it, it becomes much easier to map some of its most prevalent usage scenarios and transform those relevant pieces from the data lake into formal models and reporting packages through a data warehouse or relational database. With the data lake at your disposal, you no longer need to worry as much about tracking data origins through the transformation process since you already have a central, consolidated location from which everything is coming.
Of course, the other main consideration most organizations have when deciding whether or not to add a data lake underneath their traditional information management solutions is the cost. What’s important to remember here is that Hadoop-based implementations like data lakes tend to be very cost effective. According to PwC, Hadoop can be anywhere from 10 to 100 times cheaper to deploy than conventional data warehousing appliances. This means that if you’ve already invested in one of those more expensive appliances, adding a Hadoop architecture as well will not unreasonably drive up your infrastructure costs. Hybrid systems are becoming increasingly simpler to design as more big vendors switch to ODP and consider Hadoop integration when designing other solutions.
3. Integration Plans Matter, and You Have Options
Hadoop no longer exists in a vacuum. It used to be that most organizations would run a Hadoop implementation as a separate entity outside of the rest of their infrastructure, but that’s becoming less common as new innovations hit the market. Thinking about how you want to integrate a data lake with the rest of your systems is now a must; but the good news is you’ve got a lot more choices about how to accomplish this task than ever before.
Generally speaking, the choices you need to make here depend on whether you want a cloud-based, hybrid, or on-prem solution and whether you want to build your own clusters or invest in an appliance that has a pre-approved and pre-tested Hadoop framework loaded into it. There are, of course, different advantages to each of these options:
- Cloud: Scalable infrastructure/software, packaged solutions, rapid setup, infrastructure can be fitted to workload, low entry cost with pay per use models available, high-availability, persistent storage with powerful monitoring tools built in.
- Hybrid: Less complexity from moving data back and forth, augmentation/testing can be done fast via cloud and production solutions can be stable on-prem, more control over underlying infrastructure.
- On-Prem: Most direct control, can fully troubleshoot/integrate infrastructure in house, strong security, lower price and infinite space sacrificed for more contained and more predictable technology.
- DIY Clusters: Lower costs/better hardware reuse, easy to mix high-end master node hardware and commodity worker node hardware, easy to scale, quickly modifiable hardware configurations.
- Appliances: Standardized configuration and vendor-managed maintenance, lower setup times from optimized, integrated hardware and software, unified monitoring/management tools to simplify administration, some flexibility sacrificed for proven, tested processes.
Regardless of the approach you select, there are some overall considerations you’ll need to make when figuring out how to integrate your data lake into your wider environment. Merv Adrian, one of Gartner’s experts on Hadoop architecture and deployment, suggested a few key integration planning activities at this year’s Gartner Enterprise Information & Master Data Management Summit:
- You can test your data lake/Hadoop implementation with a disconnected pilot, but you should always be looking ahead and planning integration points.
- Define your requirements for completeness, timeliness, accuracy, and consistency of data.
- Consider data preparation/data integration tools to help out with your desired architecture. Start by auditing any of the existing vendors you have for suitability.
- Constantly conduct performance testing of your selected distribution’s data integration and ingestion.
- Get the load balanced correctly for the amount of data flowing through your environment. Your bandwidth and capacity should be able to keep up with your goals.
2. Quality Is King
The biggest fallacy around data lakes that exists in the business world today is the idea that anything can be thrown into them to obtain magically relevant results. It’s true that a data lake will accept anything you put into it, but there needs to be a larger conversation around what should be put into it before any action is taken. To avoid creating what PwC calls a “big data graveyard” full of every piece of verified and unverified information you can think of and instead build a productive, relevant data lake, you need to identify proper sources and assess the overall quality of your data lake inputs. This is the point at which the data lake approach integrates nicely with another of the methodologies currently gaining ground in the industry: MDM.
If you couple a mature MDM roadmap with a data lake implementation and go through proper data preparation and cleansing techniques, you’ll be able to avoid the typical pitfalls occurring with data lakes. You’ll also be able to make it clear to business stakeholders why there are limits and standards being placed on your data lake’s inputs. The most important thing for both MDM and Hadoop/data lakes is establishing trusted sources of mission critical information, so you can kill two birds with one stone and reap major benefits from combining these efforts.
When starting to think about a data lake in the context of MDM, you can use the same five implementation factors to understand the amount of effort needed and the analysis priorities that the solution should address. Gartner explains these five factors as follows:
- Industry: Recognize the impact that your particular area of business has on the complexity of your project. Different industries will require different levels of effort and will want larger or smaller amounts of data inputs.
- Data Domain: Consider what kinds of data are the most critical to your success. For example, if you work in a marketing firm customer data might be the highest priority whereas if you work in retail product information will matter most. Each domain comes with its own set of data collection areas and will need a wider or more specific array of descriptive and factual categories.
- Use Case: Establish some scenarios in which you would use the information in your data lake. Some new ones will come about organically once it’s implemented, but having a baseline is important. These use cases will help you focus on the areas of the data domain and industry information that matter most for your particular context.
- Organization: Think about the internal factors affecting your data lake implementation. Who are the stakeholders in this solution, and what are their priorities? What does the political atmosphere around information management look like? How many resources are available? These kinds of questions will get you to an accurate timeline for the project and will help you isolate possible trouble spots.
- Implementation: Map out the technology you already have at your disposal, as well as technology you know you want to put in place. The infrastructure and data sources available will affect your ability to meet the organizational, use case, data domain, and industry requirements you’ve been brainstorming, so getting a handle on what you have and what you can realistically add is critical to knowing which goals are attainable.
Thinking about it from the other end of the spectrum, a data lake can make a big difference in a greater MDM effort as well. One of the major objectives of any MDM initiative is working across silos to get a pulse on each of the data components that will lead the success of the organization as a whole. If implemented correctly, a data lake can be the ultimate unsiloed source of trusted information, placing all resources in a central repository from which they can be leveraged in many different contexts.
1. Experts Make a Big Difference
The final and most crucial point to grasp when venturing into the world of data lakes is that there are few efforts in which experts can help you more. Data scientists and other highly qualified professionals play a huge role in establishing the contexts within which your data lake will work. They can also aid in the process of constantly discovering new modes of analysis and establishing new sets of metadata tags. Having this expertise at your disposal will help capitalize on the full potential of your data lake and will further ensure that you stay away from trouble spots due to their heavy focus on data preparation.
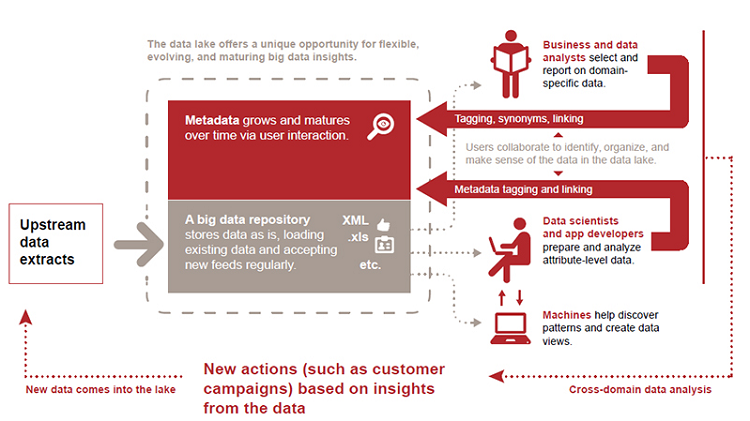
Data flow in the data lake. Digital image. pwc. PricewaterhouseCoopers LLP. Web. 1 July 2015.
When evaluating your readiness for a data lake, remember that even though the technology is new, you don’t have to single-handedly shoulder the burden of building it out for your organization. Vendors exist who have established, productized Hadoop deployments that they will put to work for you. There are also many professional services and advisory resources with expertise in this area who can ensure your implementation gets done right the first time. Letting any of these potential partners get involved with your infrastructure will pay big dividends down the road. When you start with a solid foundation, the rest of the structure you go on to build will last.
If you’re interested in learning more about Hadoop, data lakes, MDM, or any of the other concepts touched on in this article, contact Ironside today. Our trusted advisors can make these solutions a reality for you and set you on the path to your ideal position in your industry.

