Artificial Intelligence, at its core, is a wide ranging tool that enables us to think differently on how to integrate information, analyze data, and use the resulting insights to improve decision making.
With the current shift to digitization (which has been accelerated by the pandemic), customer behavior has changed significantly, along with the expectation around accuracy of AI-based predictions. We all are used to “What to Watch Next” recommendations from streaming channels like Netflix or “Suggested Products” to buy from Amazon, but now with most businesses offering the expected “Wait Time” before your a haircut, or pickup time for the food you ordered online, it is critical to manage the queue to ensure timely service that begets customer satisfaction & retention.
Many organizations want to leverage AI but are unable to mainly due to following reasons
- High cost & Time to Market
- Complexity & Lack of expertise
- Uncertainty of success of the AI outcomes
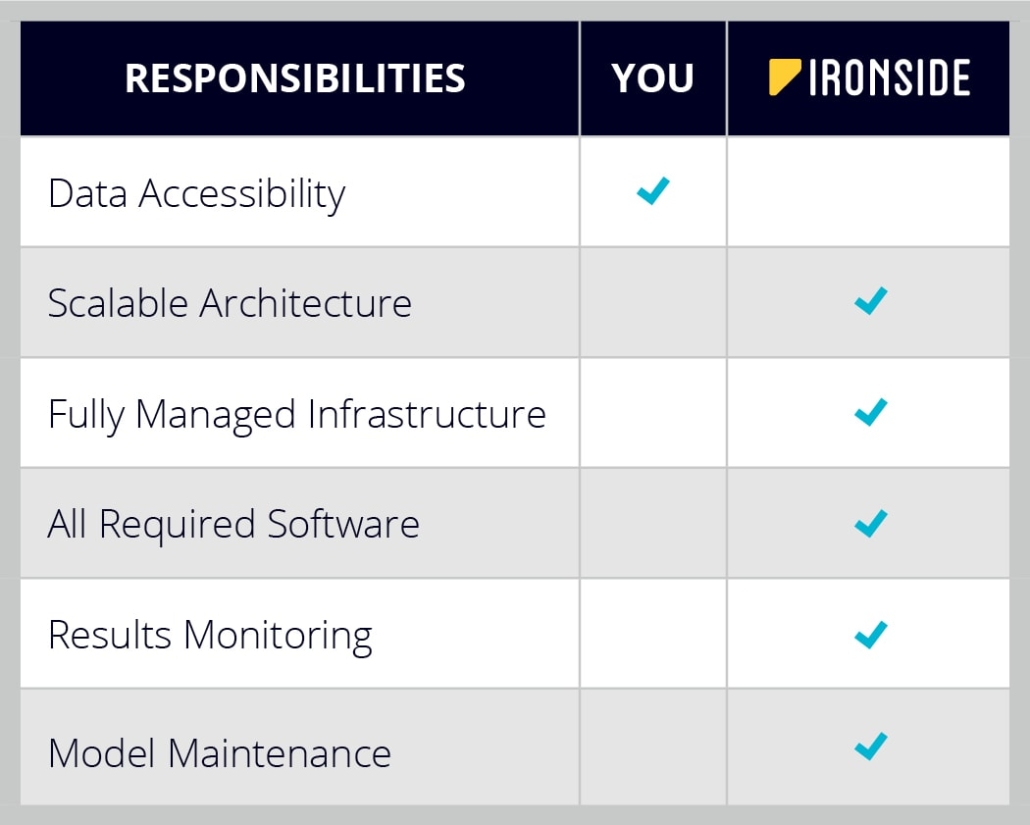
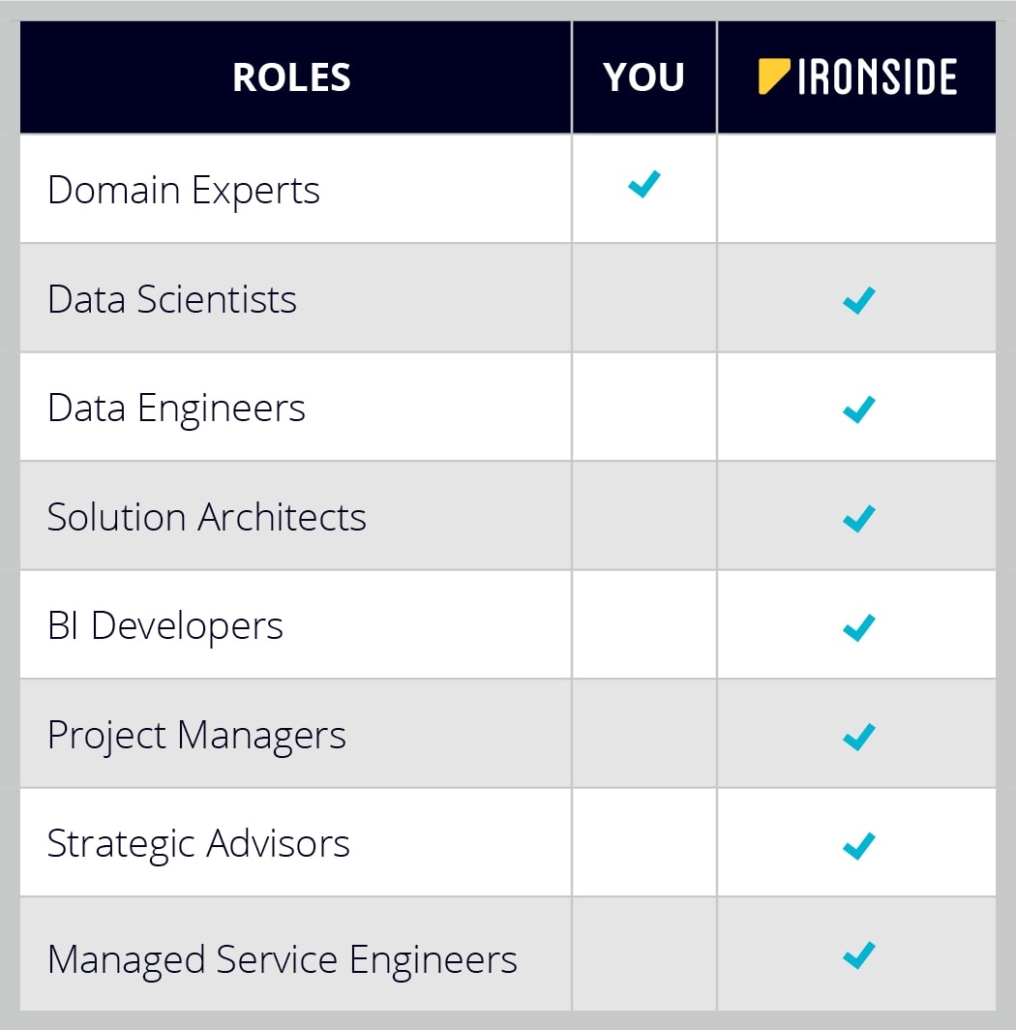
Because one of our goals is to help our customers benefit from the AI revolution, derive real business value, improve their, all in a timely fashion we at Ironside have introduced a product-style approach to Data Science called AscentAI:


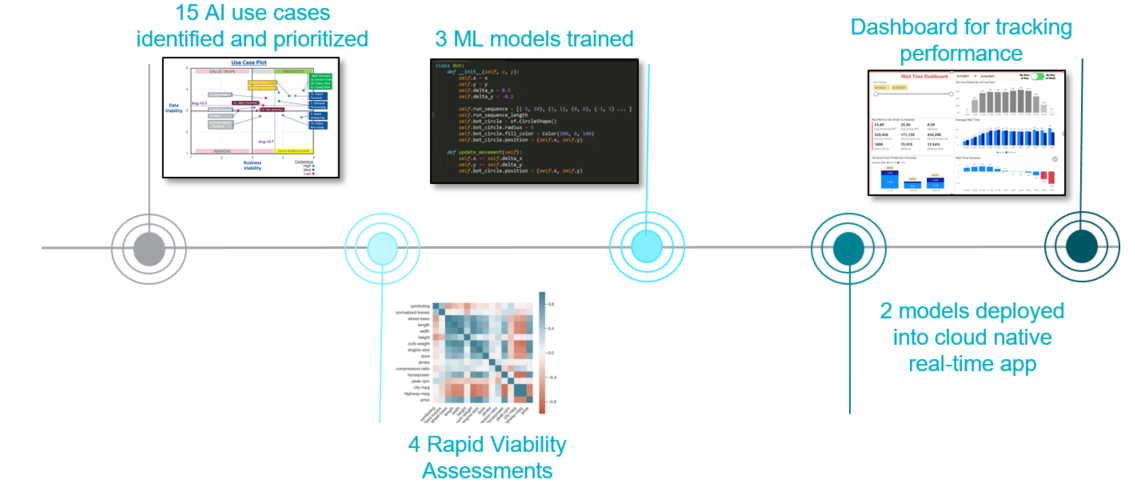
As with any project, the first steps are to identify and prioritize the business use case, define the objective, and clearly specify the goals. Next, we offer a rapid viability assessment (RVA), which ensures the model provides sufficient signal to justify productionizing the machine learning model in under three weeks.
The activities during RVA involve:
- Data collection & preparation
- The quality and quantity of the data dictates the accuracy of the model
- Split the data into two distinct datasets for training and evaluation
- Feature engineering
- Identify & define features for the models
- Model training & evaluation
- Choose different models and identify the best one for the defined requirements
- Make & validate predictions
- Measure prediction accuracy against real data sets
RVA is a decision phase, where if the AI provides more noise than actual signal, then it would not provide value in developing production-ready machine learning models. This gate-based approach ensures the customer has clear visibility into expected outcomes, and can take an informed decision on either pursuing the current use case or moving on to the next one.
If the RVA provides meaningful insights, then part of the next step is to productionize the best model, integrating it into existing business processes to start consuming the predictions.
The final step includes a performance monitoring dashboard, which is provided to monitor the performance of the models, identify the need to tune, and optimize the model due to the naturally expected skew over time. Finally, we strongly recommend model “retraining” over time at a predefined frequency to ensure the AI consistently delivers on the expected ROI.
Below is a snapshot of a real implementation of AscentAI for a customer with 1800+ stores to predict accurate “wait times” in real time in a very high volume setting on AWS cloud platform.