The integration of BI solutions within business process applications or interfaces has become a modern standard. Over the past two decades, Business Intelligence has dramatically transformed how data could be used to drive business and how business processes can be optimized and automated by data. With ML and augmented analytics movement, BI applications are vital to every organization. Analytics embedding enables capabilities such as interactive dashboards, reporting, predictive analytics, AI processing and more within the touch of existing business applications. This differs from traditional standalone BI applications that put all the capabilities of business intelligence directly within the applications on which users have already relied. Now you may ask, when should I consider embedding to maximize my ROI?
Embedding Use Cases

In this case, the integration of data & analytics is embedded into applications used by specific personas. For instance, embedding historical client information into a CSR application. One outcome will be improved decision-making based on readily available customer insights and higher levels of user adoption.

Digital transformation is all about software. Data visualization, forecasting and user interactions are must-have features of every application. Save the time you would spend coding. Embedding analytics in software not only saves cost greatly but also prominently enhances functionalities of software application.

Integration of data into your website or portal is another popular option. The benefits are obvious – information sharing provides your customers with valuable insights through a unified platform; you are able to go to market much faster since you are reaching customers directly. It helps your customers access the data they need to make decisions better, quicker and within their fingertips.
Prepare for Embedding
Ready to get started? Let’s take a look at things to be considered. At a high level, the following areas to be carefully examined before design begins:
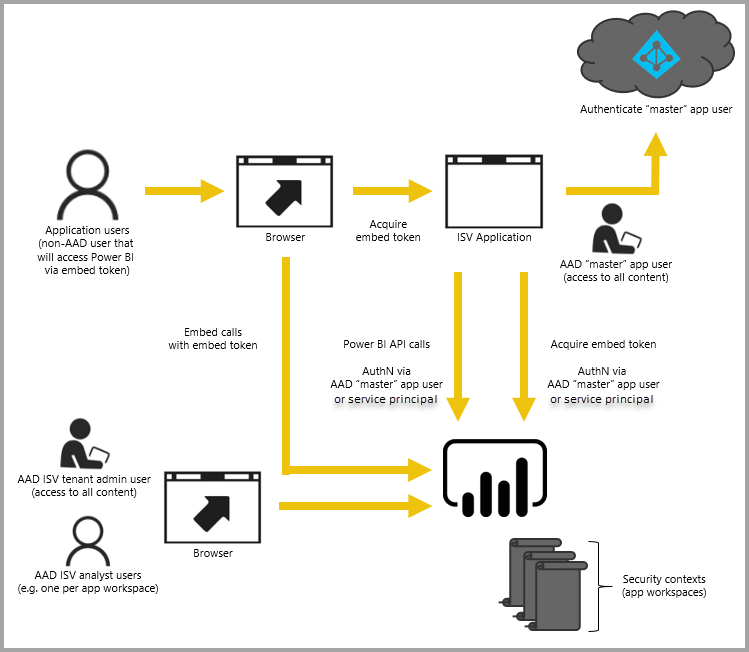
- What are the embedding integration options? Especially with regards to security, how do you enable other application access to your secured BI assets? What are the options to manage authentication and authorization for thousands of users, both internally and externally?
- Which functionalities will be open and accessible to BI embedding specifically? Typically not all UI functionalities are supported via embedding. Verify that critical functionalities are supported. Map your requirements to embedding functionalities and features.
- Cloud vs On-premise hosting. Besides management and cost concerns, your organization may have cloud strategies and road-maps in place already. If that is the case, most likely no exception for BI application including embedding. Plus source data cloud modernization is another big driver to go with cloud.
- Cost – yes, no surprise there is cost associated with BI embedding. Each BI vendor may collect fees differently but legitimately you will need to pay BI embedding based on consumption pattern even when a single application user account is leveraged. Do the math so you know how much it will be on the bill.
Next let’s examine the tool differences.
Embedding API by Leading BI Vendors
| Vendor | API | Functionalities |
| IBM Cognos | SDK – Java, .NetMashup Service (Restful)New JavaScript API for DashboardNew REST API | Full programming SDK is almost identical to UI functionalitiesSDK can execute or modify a reportMashup service is easy to web embedding, limited report output formats are supportedJavaScript API and extension for dashboard, display/editNew REST API for administration |
| Power BI | REST APIJavaScript | REST: Administration tasks, though clone, delete, update reports are supported tooJavaScript: provides bidirectional communication between reports and your application. Most embedding operations such as dynamic filtering, page navigation, show/hide objects |
| Tableau | REST APIJavaScript | REST: manage and change Tableau Server resources programmaticallyJavaScript: provides bidirectional communication between reports and your application. Most embedding operations such as dynamic filtering, page navigation |
| AWS QuickSight | SDK – Java, .Net, Python, C++, GO, PHP, Ruby, Command lineJavaScript | SDK to run on server side to generate authorization code attached with dashboard urlJavaScript: parameters (dynamic filters), size, navigation |
BI embedding opens another door to continue serving and expanding your business. It empowers business users to access data and execute perceptive analysis within the application they are familiar with. Major BI vendors have provided rich and easy to use API, the development effort is minimum, light and manageable while the return benefits are enormous. Have you decided to implement BI Embedding yet? Please feel free to contact Ironside’s seasoned BI embedding experts to ask any questions you may have. We build unique solutions to fit distinctive requests, so no two projects are the same, but our approach is always the same and we are here to help.