The Iterative Data Warehouse: A Modern Take on Centralized Analytics

The simple truth about data warehouses is that the traditional “big bang” method of building them doesn’t work for most organizations anymore. The diversity of data sources and formats we can access is constantly expanding, and taking them all on at once to form a single central repository results in a massive project that can take years to show value. That doesn’t mean we should throw out the concept of data warehousing altogether, though. In fact, there’s a better way to do it that is built on proven development practices, provides value as you go, and feels like less of a massive undertaking: an iterative data warehouse.
Sounds good, but what does that mean? First, stop thinking about all the data you have that you want to access. Instead, start to ask why that information matters to you. Start with the questions and goals that matter to your organization to put a plan together that consistently grows your data warehouse in cycles based on real priorities instead of trying to build everything at once.
How You Get There
To explore how you can get an iterative data warehouse going in your environment, we’ll take you through 4 steps:
- Focus on goals.
- Build a plan.
- Understand the data.
- Establish governance.
We’ll talk through these points more deeply in this article, giving some concrete examples based on what one of our clients is doing right now to help you see how an iterative data warehouse feeds into an end-to-end data and analytics strategy.
1. Focus on Goals
Analytics reporting relies on data. A dependable full-view data source that’s also flexible and scalable is certainly a hot item to have. Despite that, though, it’s important to remember that simply piling up all your source data in one place will not help you get actionable results. This is a common mistake that happens when organizations get caught up in defining all data instead of the right data. I’ve seen enterprise data warehouses that just contain a copy of original transitional data or have every table use 50+ keys to uniquely identify records because there are too many different data sources being pulled in.
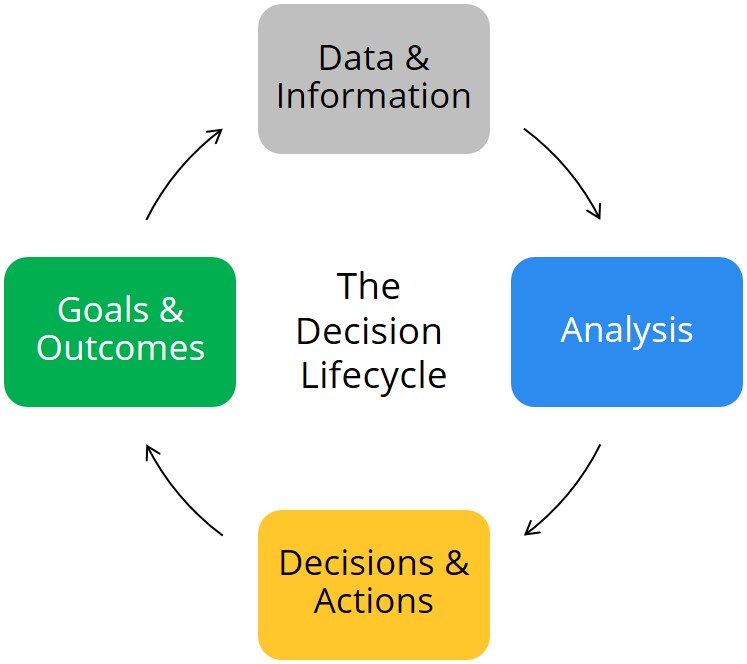
Yes, it’s true a structure like this has the most information available to search through and has 100% of the original data from your sources. That’s not the problem. The problem is it doesn’t make anyone’s life better or more efficient. It loses track of the fundamental requirements behind analytics as a whole: answer business questions, help stakeholders gain more insights, and drive better decisions and actions.
The way you keep these points in focus is by starting with goals instead of data. All the pieces of information you pull into your data warehouse should have a reason why they’re being included. If you set specific project goals before you even look for data, you will view all the data you find through the lens of those goals and will end up with relevant, valuable results. At Ironside, this is how we start every engagement we do, no matter what type.
Goals in the Real World
One of our clients has an intuitive understanding of this first phase of iterative data warehouse development. They started out asking about specific goals and questions they had and how they could get those answers out of the rich data stores they knew were available.
Our client had recently formed an Information Systems team to get custody of their data and establish centralized processes and tools around it. As they got started, the team didn’t just feed a bunch of data into a single location and call it good. Instead, they began asking business stakeholders what information they needed to act effectively in their roles and continue the massive success the company was enjoying. Based on this information, they developed several core project goals:
- Promote transparency by showing staff and shareholders a regular, clear picture of company performance.
- Standardize business approaches through an authoritative view of key metrics for all locations, allowing for comparison and accurate performance milestones.
- Add new technology solutions without the need for more hardware or maintenance overhead.
- Build a culture of foresight focused on seeing how promotions and company actions affect their customer base and producing accurate finance forecasts at the speed of business.
2. Build a Plan
With goals identified, you can move on to defining a good plan for implementing them. Creating an IT-driven, or mode 1, data solution definitely requires collaboration and teamwork across all activities, including requirements gathering, consolidating data, business logic transformation, cleaning, and securing data, among others. It begins with aligning your organization’s leadership and strategic vision with the effort, as well as collecting accurate data vertically and horizontally across all business units.
The plan you create should map to the decisions and actions that will help you best achieve the goals you set, and should contain initial direction around where to go to get the data you’ll need. Remember, just like the wider analytics process you’re deploying, your plan should be iterative and should allow flexibility as you get deeper into the project.
A Practical Roadmap
Now that our client had some guiding principles, they could decide on cycles of development for their iterative data warehouse, bringing in different pieces of information over time based on high, medium, or low levels of need in the organization. They then mapped out project steps in alignment with their findings:
- Implement the data warehouse – set up the infrastructure and configure connections
- Prioritize data sources across the company – top contenders for most value were sales, operations, customer, and finance data coming from multiple systems such as the client’s POS applications, finance team spreadsheets, Salesforce CRM system, and facilities data
- Put a Managed Services strategy in place – free the internal team to provide analytics value instead of administration by transitioning technology delivery and maintenance to Ironside
- Clean, consolidate, and prepare prioritized data sources to be centralized in the data warehouse – agile, multi-pass approach adding information in cycles over time
3. Understand the Data
A centralized data source like an iterative data warehouse is mainly targeted to and designed for regular business analysis. The goal is to have an integrated data store that ideally holds all the data needed to answer recurring questions. Understanding the source data used to populate your centralized source in its original context is critical to correctly transforming that data and finding the sources that meet your goals and match your plan. For example, in a CRM system a customer may mean a company or individual depending on the sales type (B2B vs B2C).
Exploring the data sources you’re targeting and evaluating their quality before you make any moves toward adding them to a data warehouse will help you see the best way to go about bringing them in. This is the other reason why an iterative process is so important. Evaluating data sets as analysis goals get formed lets you focus on processing one area instead of everything at once.
Working through the Cycles
With their plan in place, our client began diving deeper into the data sources they had tagged to add as their first cycles in the iterative data warehouse. They cataloged data sources across the company, finding out what kinds of historical data lived in what systems and platforms. The departments whose reports were most critical drove what got marked for data warehouse transformation. Operations, finance, sales, and marketing got priority, so we worked to define metrics that would represent those roles effectively and help establish regular flows of useful information to those places.
The client quickly started finding through exploring their priorities that the different data sources would all need some work before they could get centralized. This is something that would have been very overwhelming if they had been looking at everything at once, but since they knew which areas mattered most they were able to decide where to start cleansing and transforming first to make the biggest impact, which moved them toward the next phase of infrastructure development: governance.
4. Establish Governance
Data governance plays an essential role in defining how data should be processed, transformed, consumed, and protected. It enables organizations to collect and consolidate information vertically and horizontally, as well as root out both business and compliance risks. Data protection is a very common and critical practice; however overly complex security models make data access too difficult, taking away from a system’s ability to meet its core goals. Carefully selecting the point where you apply security is vital to preventing this.
The other major benefit of having a governance strategy in place is establishing a shared vocabulary. This usually takes the form of an additional set of standards that simply catalogs what the official naming conventions are for different metrics and data types. The best way to gather the requirements for this is through collaborative team meetings with your stakeholders that help you understand how they think about and refer to their departments’ key information. With this resource created, you’ll be certain that everyone in the organization is referring to things the same way and will have a transformation standard when you take in new data or results found through data discovery efforts.
Combining the Silos
Prior to starting their progress toward an iterative data warehouse, our client had been very fragmented. Each of their departments worked in its own bubble, focused on its day-to-day tasks and questions with no thought of the whole organization. None of them knew how the others measured success or failure, which meant they weren’t aware of how much they shared in common in terms of the underlying data they needed.
As the Information Systems team started uncovering the details of the data sources identified in the roadmap, they started realizing all the places where those sources could have an impact across many of the functional areas in the company. This led to more brainstorming sessions and interviews with stakeholders to hear how they discussed their data priorities and find common ground across the different groups. This built up a single authoritative set of definitions and metrics terms that could be relied on no matter where they went in the organization.
Conclusion: Building on the Iterative Data Warehouse
I hope the points outlined here and the insights from our client’s perspective have helped you get a picture of how an iterative data warehouse begins taking hold in an organization and providing value continuously over time. The other important thing to remember is that it’s only the first step. With a system like this in place, you can build out more sophisticated analytics practices like data discovery and data science, enabling ad hoc business answers and accurate predictions around your key metrics. In fact, the client we’ve been discussing here already started piloting initiatives like these shortly after their first data cycles were completed.
It’s true that implementing an enterprise data warehouse all at once competes with the practicalities of daily business and delays results. This doesn’t mean, however, that you should stop focusing on the value of a centralized data resource connected to an enterprise BI platform. These structures have stuck around for a reason; we just need to change how we think about them to match the modern analytics landscape and move in a more flexible direction.


