ETL vs. ELT – What’s the Big Difference?

ELT is a term heard increasingly in today’s analytic environments. Understanding what it means, and how you can make use of it, requires understanding the traditional nature of how data warehouses are loaded and how data movement tools work. That’s why we’ve pulled this article together: to break down the ETL vs. ELT divide and show you where the similarities and differences are.
ETL – Tactical vs Strategic
Traditionally, ETL refers to the process of moving data from source systems into a data warehouse. The data is:
- Extracted – copied from the source system to a staging area
- Transformed – reformatted for the warehouse with business calculations applied
- Loaded – copied from the staging area into the warehouse
How these steps are performed varies widely between warehouses based on requirements. Typically, however, data is temporarily stored in at least one set of staging tables as part of the process. The extract step might copy data to tables as quickly as possible in order to minimize time spent querying the source system, or the transform step might place data in tables that are copies of the warehouse tables for ease of loading (to enable partition swapping, for example), but the general process stays the same despite these variations.
Numerous tools exist to assist with the ETL process, such as DataStage, Informatica, or SQL Server Integration Services (SSIS). These tools all work in a similar fashion – they read data from a source, perform any desired changes, and then write it to a target. These three steps are like the extract, transform, and load steps, but they can be done multiple times over the course of a warehouse load. For example, a source extract job might read the data, add simple debugging information, then write it to a staging table. A transform job might then add business logic and write the data to a dimension staging table. Finally, a load job would then copy the data into the warehouse dimension. That’s three separate ETL tool operations for a single warehouse “ETL” step. At the other end, an entire warehouse load could be placed inside a single ETL job, so that tool ETL and warehouse ETL are literally the same.
ELT Defined
These two definitions of ETL are what make ELT a bit confusing. ELT is a different way of looking at the tool approach to data movement. Instead of transforming the data before it’s written, ELT leverages the target system to do the transformation. The data is copied to the target and then transformed in place.
ELT makes sense when the target is a high-end data engine, such as a data appliance, Hadoop cluster, or cloud installation to name three examples. If this power is there, why not use it?
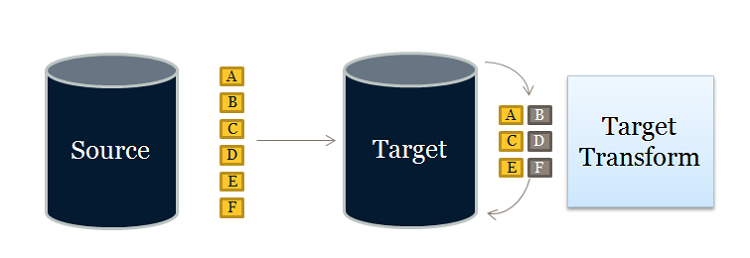
ETL, on the other hand, is designed using a pipeline approach. While data is flowing from the source to the target, a transformation engine (something unique to the tool) takes care of any data changes.
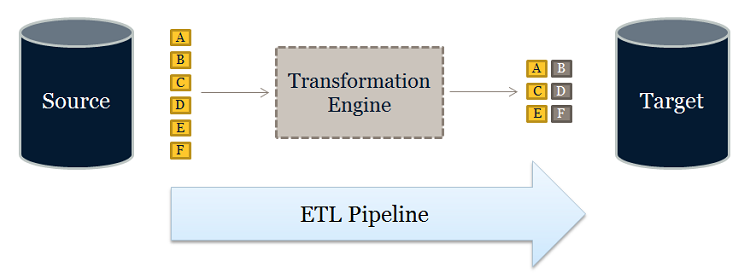
Which is better depends on priorities. All things being equal, it’s better to have fewer moving parts. ELT has no transformation engine – the work is done by the target system, which is already there and probably being used for other development work. On the other hand, the ETL approach can provide drastically better performance in certain scenarios. The training and development costs of ETL need to be weighed against the need for better performance. (Additionally, if you don’t have a target system powerful enough for ELT, ETL may be more economical.)
ETL Pipeline Development
Like a pipeline, an ETL process should have data flowing steadily through it. Unlike physical pipelines, ETL tools are capable of expanding to hold more data (like a bulge in the pipeline). The more they try to hold, however, the more likely they are to run out of memory or disk space and “burst.”
The classic example of this is sorting. To sort data going through a pipeline, all of the data has to be held up – you can’t send anything farther until you’re sure it’s sorted, and you can’t be sure until the last piece of data is read in (for example, what if the last piece of data is first in the sort order?). This means the ETL tool is holding the entire data set before any output is written. On the other hand, if the data comes in sorted, the tool can send each piece of data all the way through the pipeline without waiting for the next piece.
Why is this faster? The ETL tool is already reading and writing the data (generally at high speeds). Processing the data while it moves through takes no time relative to the time required to read from or write to disk. Even complex calculations performed in memory are a negligible performance hit. Only when the pipeline gets held up or clogged will there be issues.
Many ETL tools will also allow parallel execution – creating multiple pipelines and splitting the data between them. This will drastically improve performance, but only if the data can be split without affecting the computation.
Designing a proper ETL pipeline can take some work, but the payoff can be tremendous.
ELT Development
The specifics of ELT development will vary depending on the platform. For example, Hadoop clusters work by breaking a problem into smaller chunks, then distributing those chunks across a large number of machines for processing. The problem is solved faster because it’s being done in parallel. This requires careful design to make sure that the act of splitting the problem can be done without affecting the answer. Some problems can be easily split, others will be much harder.
Other platforms (such as cloud databases or appliances) will have fewer constraints visible to developers.
In all cases, developers need to be aware of the nature of the system they’re using to perform transformations. Some systems (such as hardware appliances) have enough resources to handle nearly any transformation, but others require careful planning and design.
Conclusion
ELT is an excellent tactical tool for loading a data warehouse. It requires a powerful system in place as the target, but more and more warehouses are being built with such systems in mind to meet ever-growing analytic needs. As with any tool, knowing when to use it is at least as important as knowing how to use it. Ironside can provide strategic direction and/or technical support in data integration and management. Contact us today to discuss which options fit your environment best.

About Ironside
Ironside was founded in 1999 as an enterprise data and analytics solution provider and system integrator. Our clients hire us to acquire, enrich and measure their data so they can make smarter, better decisions about their business. No matter your industry or specific business challenges, Ironside has the experience, perspective and agility to help transform your analytic environment.

