Five Essential Capabilities: Data Wrangling

This is part two in our five part series on the essential capabilities of the competitive data-driven enterprise.
For decades, data integration and modeling have been done in either of two likely places: The enterprise ETL or Data Warehouse environment (IT Developers) or Excel (Analysts). Currently the status quo is being challenged in some of the following ways that highlight the importance of empowering domain and subject matter experts to wrangle and model their own data.
New Methods Dictate New Data Models
Modern data visualization tools work best (or are accessible to the greatest number of non-technical analysts) when used in conjunction with very flat (lots of repeating values) and very wide (sometimes hundreds of related fields on a single row) data sets. This is not how most databases or even data warehouses are modeled. In addition, data preparation for machine learning most often involves similarly transforming data into even flatter and wider (sometimes thousands of fields wide) data sets, and often it is more effective to see raw data as opposed to a limited or sanitized view that is presented in most data warehouses.
The Burden of Proof (of Value)
Data analysis by any means is an iterative and experimental process that benefits from trial and error by way of rapidly discarding less useful data and testing out new data elements until a conclusion is met. Forcing such a fluid process through a centralized ETL or data management protocol is not only unnecessarily expensive, but also slows data analysis velocity to near zero. If the core value proposition of centralized data management is applied data governance, why incur a premium for concepts that in their infancy have unknown value to the organization and a high probability of being discarded? The lean data-driven enterprise has an imperative to empower citizen analysts to build their own business cases for more governance, and to do so as quickly and accurately as possible.
The Need for Speed
Centralized ETL tools that are used to model and populate the data warehouse require specialized skill sets, are operated by a small group of limited centralized resources, and because of the high level of quality assurance associated with the data warehouse, are costly to operate and have longer development times. Rarely are these specialized resources also the business problem domain experts, and as such a lengthy process of communicating inevitably incorrect or incomplete business requirements must be carried out before any development can begin.
On the opposite end of the spectrum, most analysts who have ever had to rely upon a spreadsheet as their only self-service means of data manipulation will agree that it is often time consuming, functionally primitive, error prone, incapable of handling large data sets, and embedded logic is difficult to interpret and understand when the workbook is inevitably transitioned from its creator to a new employee. In addition, many analysts need to integrate diverse data formats from web services, geo-spatial databases and other non-standard formats that a spreadsheet is ill-equipped to handle.
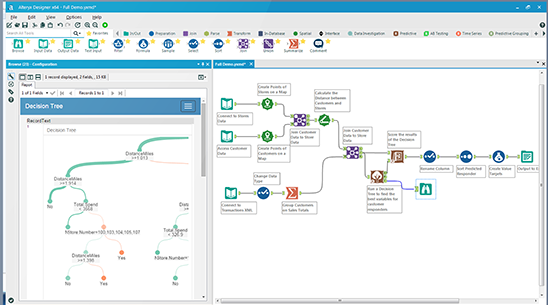
An Alteryx designer workflow. Many popular data wrangling tool sets use a visual workflow interface to show how data is being shaped as it flows along a virtual assembly line.
The Evolving Role of Centralized Data Management
Centralized data management teams are now acknowledging that modeling data into the data warehouse when its context for usefulness and value to the organization is entirely unknown is at best a risky proposition, and at worst a vast waste of time and resources. Increasingly these centralized units are focusing their energy on deploying agile forms of governance that allow analysts to discover, understand and trust business data (data catalogs, data governance and master data management) and then use self-service data preparation tools to model the data on their own to make the business case or determine the needs for the additional governance that a data warehouse could provide on a sustaining basis.
In larger enterprises we have also seen the stature of centralized data management shift almost entirely from being the ETL and DW operators (a restaurant serving prepared meals to order) to managing master data, data quality and provisioning vast quantities of raw information through new mechanisms such as the data lake (a grocer or wholesale food distributor providing fresh ingredients). In this analogy, the business analyst has evolved from restaurant patron to aspiring chef, and self-service data preparation tools are a test kitchen stocked with cookbooks and every fit-for-purpose tool or utensil you could imagine.
Data Wrangling Essentials
A self-service data preparation platform should enable business users to:
- Rapidly build data flows within a friendly and intuitive user interface
- Integrate information of various types and sources (databases, files, web services, spatial sources, etc.)
- Easily scale to process very large volumes of data if necessary
- Easily share data flow recipes to allow others to benefit or build upon prior work
- Easily schedule and automate the processing of data flows
- Integrate with your organization’s data visualization and machine learning platforms of choice
Next Up: Automated Machine Learning
For decades, the methods of data mining, predictive modeling, and now machine learning have been the exclusive realm of statisticians and data scientists. Recent technological innovations have raised the prospect of putting these powerful tools in the hands of business analysts everywhere. Next up we explore how leading organizations are going beyond data visualization and business intelligence, and adding machine learning to every citizen analyst’s workbench.
About Ironside
Ironside was founded in 1999 as an enterprise data and analytics solution provider and system integrator. Our clients hire us to acquire, enrich and measure their data so they can make smarter, better decisions about their business. No matter your industry or specific business challenges, Ironside has the experience, perspective and agility to help transform your analytic environment.

