Agile Data Warehousing with Spark

Data discovery is a “new” technique that takes a less formal and more agile approach to analyzing data. Okay, well, it’s not really new — people have been doing this with spreadsheets for decades — but the products that support it have improved greatly and have forced a more formal consideration of these techniques. The data discovery approach produces insights very quickly, but it also encounters challenges when dealing with data transformation. Most data discovery tools are limited in their ability to manipulate data. Additionally, understanding relationships between different data entities can require expertise that some users may not possess. In order to enable agile data discovery, organizations need agile data warehousing.
Further complicating the analytics environment is the presence of cluster-based computing, often referred to as big data. A big data cluster is a very powerful tool for processing unstructured data, high volumes of data, or real-time data streams. All of these scenarios present very different challenges from a traditional data warehouse with a nightly load cycle.
Spark is a platform that simplifies data movement in clustered environments. In order to understand how it can be used, it’s helpful to compare it to a traditional data warehousing environment.
SQL vs. ETL
Data warehouses exist to store data in a format suited to reporting needs: a format that performs better and is easier to access. Moving the data into the warehouse requires code of some sort. This can be (and often is) as simple as a series of SQL statements against a relational database, such as INSERTs to place the data in tables, UPDATEs to perform business logic and transformation from transactional to dimensional format, and other similar functions. Often, this approach is used because it’s what people know – if a company has databases, they probably have SQL experience.
A SQL-based approach to data movement has limitations, however. One of the largest is performance. Each SQL statement performs independently on the data, which is then written out to the target database. Multiple updates require scanning the data set repeatedly, writing changes to the database each time. This can add up to a large performance penalty.
ETL tools like DataStage, SSIS, or Informatica provide a solution to this challenge. By using a pipeline approach to data movement, they can perform multiple transformations while moving the data from one place to another. Well-written ETL can transform the data in the same time that it takes to move it — and good ETL tools are very fast at moving data. ETL tools result in a more efficient approach to data movement, which makes data warehouses easier to load, maintain, and use.
Relational Databases vs. Big Data
We are experiencing an explosion of data — both in volume and in diversity. Big data deals with data that has grown in volume, speed of delivery, or complexity (such as unstructured data). The most common platform for big data is Hadoop. Hadoop provides a system for storing data (HDFS, or Hadoop Distributed File System) and a clustered platform for working with that data (MapReduce). Since the data is stored as files, it can be of any type, structured or unstructured. Having a cluster working in parallel provides speed; working with files provides flexibility.
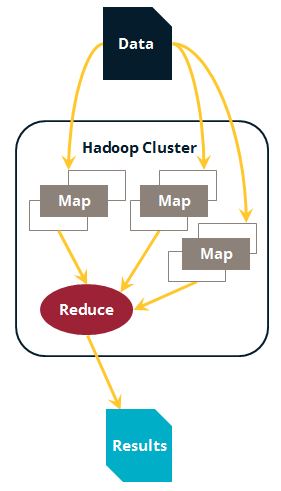
In order to process this data, programs will read it from the file system, perform some activity divided amongst the nodes of the cluster, then write the results back out to the file system. For complex transformations there may need to be multiple programs that work one after the other — each one writing data back to the file system. Sound familiar?
Spark: ETL for Big Data
Spark was designed as an answer to this problem. Instead of forcing data to be written back to storage, Spark creates a working data set that can be used across multiple programs. In the same way that ETL optimizes data movement in an SQL database, Spark optimizes data processing in a cluster.
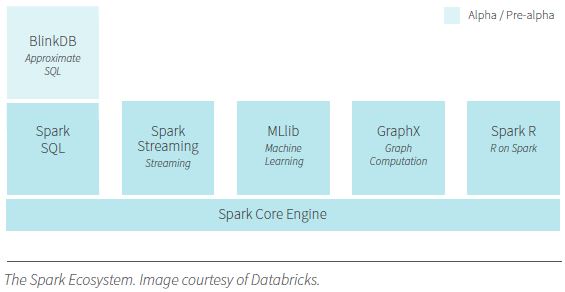
With Spark, multiple data manipulation modules can be strung together to perform sophisticated data manipulation, analysis, and integration without the performance hit of writing back to disk constantly. Developers can work with users to create and change these modules so that the results can be leveraged for data discovery.
Flexible Data Manipulation
Big data clusters are often used for data discovery — agile exploration of data to quickly produce insights. Traditional enterprise reporting tools are not very effective at this task. Newer tools focused on data discovery allow for quick manipulation and reformatting of data.
Unfortunately, though, these tools are designed to quickly visualize data, not to transform it. Working with new data sets can be difficult — the data may not match existing formats or may need changes to be meaningful. In a big data environment, unstructured data requires processing to produce some sort of structure on which to perform analysis (identifying sentiment, word counts, etc.). Data discovery tools are not built for this. ETL tools can do this type of transformation, but they are not built for big data formats and generally involve a design and deployment cycle that takes too long for data discovery (this may be an institutional limitation as much as a technical one — many large companies have policies in place around relational database and ETL development).
Spark provides the performance necessary for data discovery while also simplifying the data transformation process. Spark requires coding, but uses languages that are more familiar to data scientists, such as Java, Python, R, and Scala. Unlike relational databases where changes are tightly controlled in production, big data clusters are often intended for more open coding as a way to promote data exploration, and Spark capitalizes on this model.
The combination of more familiar languages and more open policies is a high-performance framework for modifying information stored in big data clusters quickly enough to be useful for data discovery, setting up an agile data warehousing activity stream relevant to these newer formats. Over time, insights gained from this process will likely be moved into relational data warehouses with important transformations being coded into ETL. Without the agility of data discovery processes, however, these insights and logic may never be identified.
Summary: Agile Data Warehousing Made Real
Leveraging big data poses many significant challenges. Without technical support to transform the many data types and condense high volumes of data into useful aggregations, data discovery tools will have a hard time getting a handle on the vast array of information that may be available. With Spark, creating intuitive, consumable data sets becomes much easier and faster, enabling a more agile data warehousing environment.
This is just one of the many approaches that Ironside can help you implement using Spark. Check out these additional articles for some other ideas: