Crunching Web Logs with Spark: Handling Your Site’s Big Data

Don’t think you have big data? Chances are you do. The fact is if you have a website, you have big data. Web servers capture and store events related to user traffic. The web logs they generate essentially tell the story of what users did when they visited your site. This information can provide your organization with extreme business value.
If you think you have big data to analyze from your website, you may want to look into Apache Spark. It’s easy to get started with and makes short work of analyzing your web logs. It’s actually pretty fun to work with, too. If you enjoyed playing with LEGOs as a kid, you may have a childhood flashback with Spark.
What Is Spark?
![]()
Apache Spark is a framework for big data processing and analyzing distributed data. Since it doesn’t have its own distributed data infrastructure, it isn’t a replacement for Hadoop. Instead, it can be viewed as a replacement for Hadoop’s MapReduce engine.
MapReduce stores data on a computer’s disk while Spark stores it in memory. Since it doesn’t have to rely on network and disk I/O, it can process data faster. This is done using the concept of a Resilient Distributed Dataset (RDD). RDDs store data in-memory, and only persist it to disk when needed, reducing a lot of the read/write operations.

Spark also allows for the use of higher-level programming languages, such as Scala, Python, and Java. This allows you to quickly develop Spark-based programs, and is where software development intersects with data management and analytics.
Spark for Web Logs
So why does all this matter? Well, I recently worked through a use case employing Spark to process web logs. The goal was to analyze traffic, specifically download behavior. I explored Databricks’ Spark solution using their Python notebook. Databricks is built on Amazon Web Services, making it extremely easy to get started. I figured I couldn’t go wrong, working with the company whose founders invented Spark in the first place!
As I worked through the development of my Python notebook, I couldn’t help but think about LEGOs. The notebook concept allows you to write snippets of code that execute discrete steps. For instance, you can parse large volumes of log files, enrich data, filter data, store it in specific locations, etc. To me, this was like being handed a random bucket of LEGOs – I was able to pull from a large number of varying bricks to create my masterpiece!
The Application
For my web log use case, I was able to construct a notebook that parsed space-delimited files, pulling out key pieces of data (IP Address, HTTP Method, Endpoint, Response Code, etc). I was then able to reach back into the LEGO bucket and create Python functions that enriched my data – performing GeoIP lookups, parsing out file names and extensions, filtering out bot traffic, and other similar tasks. All of this was quickly executed in-memory using Spark.
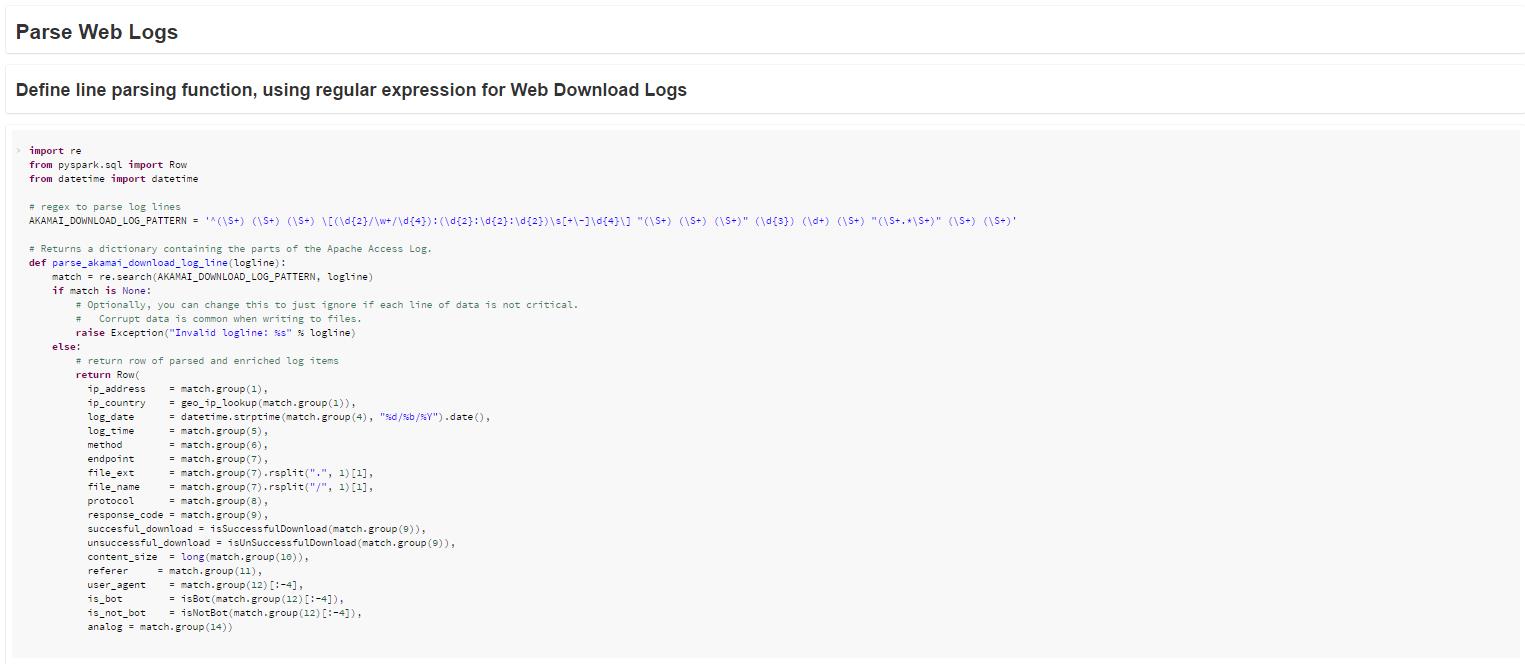
Spark also provides another construct called a DataFrame. The DataFrame concept is essentially equivalent to a table in a relational database. It allows you to access your data using SQL.
I decided to convert my RDD into something more SQL-friendly and took advantage of a DataFrame. I was able to write my DataFrame out as a parquet table on Amazon. Using an ODBC connection, I was then able to hook my data visualization tool (in this case QlikSense) to it, analyzing my data in a familiar way.
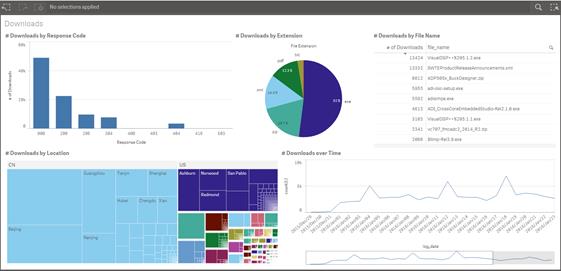
After I completed my basic web logs use case, I decided to expand the scope by pulling in a simple time dimension and storing it as a CSV file. Spark allowed me to read the time dimension CSV file right into a DataFrame using a single line of Python code.

Another simple line of code allowed me to easily join my web log DataFrame to my newly imported time dimension DataFrame.

Expanding the Scope
That’s when my LEGOs analogy gave way to something a bit more interesting. I started asking if my notebook was serving as an ETL tool, creating a data warehouse on the fly. Instead of working with operational data stores, I was working with files.
I believe my thought process was validated when I met up with some of the folks from Databricks. They mentioned that they were starting to see an interesting use case for Spark. They said they were seeing customers gravitate towards Spark for “agile warehousing”. I’m still rubbing my neck from the double-take I did. They were seeing the same thing that unveiled itself to me through my web logs use case.
This agile data warehouse concept alone should merit your further consideration. No longer are you constrained by a traditional EDW process, pulling in data from other databases. You are now free to dive into as many buckets of LEGOs as you can find, searching for valuable business information you may never have considered. You can also view it as enhancing your EDW, building on top of it, much like you would take a packaged LEGO kit, build it, and then make it better by going into your big bucket of random LEGOs.
The Bottom Line: Why Spark Matters
Whether or not you are a fan of LEGOs or you believe Spark can serve as some sort of agile data warehouse, you should seriously consider adding Spark to your arsenal of analytics solutions. It allows you to analyze and integrate data from once unnoticed sources, proving you with new insights into your business.
Spark’s applications go far beyond the examples we’ve discussed here. It’s also a great tool for predictive analytics, especially in the areas of data prep and machine learning. If you’d like to know more about Spark or any other aspect of data handling, our Information Management team is ready and willing to help. We can deliver all the data sources critical to your success in a way that makes them understandable and actionable.


