Ironside Presents at Boston Scalable R Analytics Meetup

Ironside experts Dan Gouveia and Chi Shu recently got the chance to share knowledge with our local analytics community at the Scalable R Analytics Meetup in Cambridge, MA. Presenting to a packed room, Chi and Dan dove into several ways that R’s powerful data science capabilities could be scaled to apply to much larger, enterprise-level data sets. They demonstrated how to achieve this scalability both with dashDB, a cloud data warehouse, and Spark, a big data-oriented parallel processing framework.

Scalable R Analytics Presentation Highlights
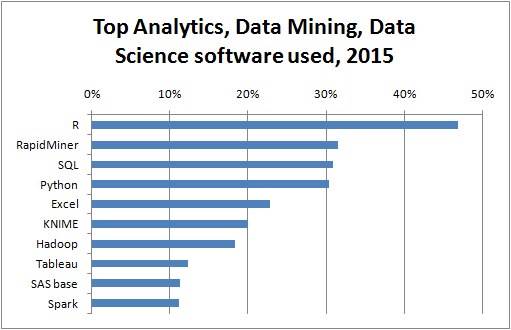 The presentation kicked off with an overview of R itself, its capabilities as both an open source programming language and a tool for statistical analysis/data mining, and the reasons why it’s become the most adopted advanced analytics tool in the space. It then focused on how despite all its versatility and power, R alone is not enough to establish an enterprise-wide predictive analytics strategy due to its processing and data loading limitations.
The presentation kicked off with an overview of R itself, its capabilities as both an open source programming language and a tool for statistical analysis/data mining, and the reasons why it’s become the most adopted advanced analytics tool in the space. It then focused on how despite all its versatility and power, R alone is not enough to establish an enterprise-wide predictive analytics strategy due to its processing and data loading limitations.
This conversation of course led into the broader purpose of the meetup: showing how R analytics can expand outward to handle enterprise-sized questions. Dan and Chi covered several topics to accomplish this:
- Early approaches to scaling R for big data with MapReduce
- How dashDB incorporates R into its built-in advanced analytics functionality and allows R script development to generate statistical models
- How the DBR package in dashDB allows further in-database actions, such as creating data frames, creating queries that generate R data frames, and adding modeling algorithms
- How Spark DataFrames enable R analytics in Spark and how SparkR allows you to run Spark from within R
Value Delivered
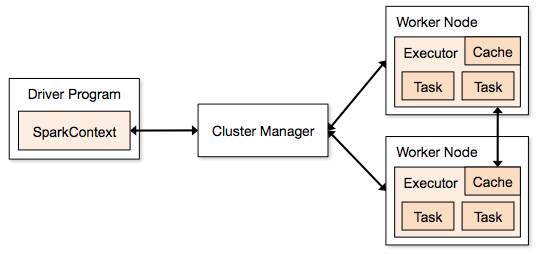 Dan and Chi’s presentation provided not only overviews of the different techniques for scaling R analytics but also practical demos drawn from real-world consulting experiences and in-depth visual walkthroughs of the infrastructure and workflows required for each solution covered. These dove into how dashDB and Spark could be configured to work with R and showcased additional tools to help augment these capabilities.
Dan and Chi’s presentation provided not only overviews of the different techniques for scaling R analytics but also practical demos drawn from real-world consulting experiences and in-depth visual walkthroughs of the infrastructure and workflows required for each solution covered. These dove into how dashDB and Spark could be configured to work with R and showcased additional tools to help augment these capabilities.
“We thought it would be nice and refreshing to present some of the stuff we’re doing heuristically,” Dan said while introducing the first topic of the evening.
This practical focus is what brought the greatest value to the audience throughout the presentation. From executing R scripts using dashDB in-database analytics to building SparkR workflows using Jupyter Notebook, to combining dashDB and Spark into a single solution using RStudio, Dan and Chi left their audience with many tangible takeaways they could begin executing in their environments.
“The whole purpose of scaling R up with dashDB or Spark is so that it can handle large volumes of data spontaneously. Extending it to the wider enterprise means that people can analyze structured and non-structured data from different sources more easily.”
– Chi Shu, Data Scientist, Ironside
If you’re interested in learning more about Dan and Chi’s presentation or seeing the demos that they presented, contact us to set up discovery call. Keep an eye out for Ironside consultants at other local analytics events! We’re always happy to discuss your analytics needs and help you reach your organization’s goals.