The AWS Summit New York 2024 was an exhilarating event to showcase cloud innovation, AI advancements, and industry best practices. At this action-packed day hosted at the Jacob K. Javits Convention Center, this year’s Summit brought together thousands of professionals, technology enthusiasts, and AWS experts to explore how cutting-edge AWS technologies can be used to revolutionize industries and empower businesses.
At this year’s Summit, over 170 sessions were offered covering a wide range of topics and technical depth, ranging from level 100 (foundational), level 200 (intermediate), level 300 (advanced), and level 400 (expert). Within these sessions, many AWS experts, builders, customers, and partners shared their insights on numerous topics such as generative AI, analytics, machine learning, industry specific solutions, and many more. Individuals were able to customize their own agenda ahead of time and choose from lecture-style presentations, peer-led discussions, and explore the Expo to learn about the numerous advancements of AWS technologies and deepen understanding of best practices. Dr. Matt Wood, VP for AI Products, AWS, hosted the keynote session to unveil the latest launches and technical innovations from AWS and demonstrate products and real-world success stories from AWS customers.
Below is a detailed look at some of my key takeaways and trends that summarizes this year’s Summit:
1. Amazon Bedrock
Stemming from the heavy emphasis on generative AI and its capabilities, one of the most exciting announcements from the Summit was the introduction of new capabilities in Amazon Bedrock. Amazon Bedrock is AWS’s relatively new service designed to simplify the creation of AI applications. The service provides access to pre-trained foundation models from leading AI providers, and enables businesses to build, deploy, and scale AI-driven solutions without deep expertise and extensive effort. In addition, the many key features of Amazon Bedrock allow users and businesses to build innovative AI solutions effectively and efficiently while ensuring scalability and compliance. The fundamental idea of this service is to revolutionize how companies develop and deploy generative AI applications, making it easier to integrate cutting-edge technology into existing workflow while significantly reducing computational costs.
At this year’s Summit, additional features of Amazon Bedrock were introduced to enhance company knowledge bases with new Amazon Bedrock connectors for Confluence, Salesforce, SharePoint, and web domains. In doing so, companies can empower RAG models with contextual data for more accurate and relevant responses.
Lastly, Guard Rails and Guard Rails API were introduced for Amazon Bedrock to contribute to the following:
- Bring a consistent level of AI safety across all applications
- Block undesirable topics in generative AI applications
- Filter harmful content based on responsible AI policies
- Redact sensitive information (PII) to protect privacy
- Block inappropriate content with a custom word filter
- Detect hallucinations in model responses using contextual grounding checks
Businesses and customers can apply safeguards to generative AI applications even if those models are hosted outside of AWS infrastructure. It is estimated that up to 85% of harmful content can be reduced with custom Guardrails.
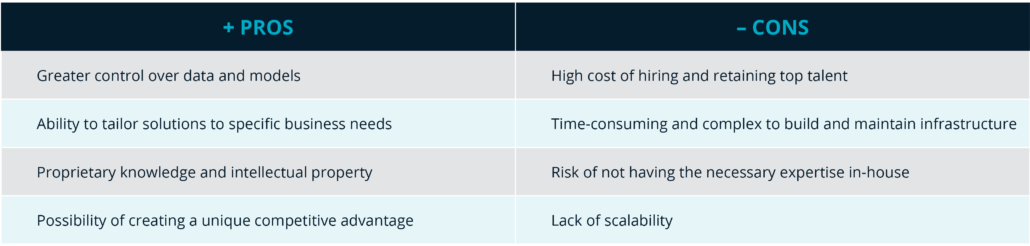
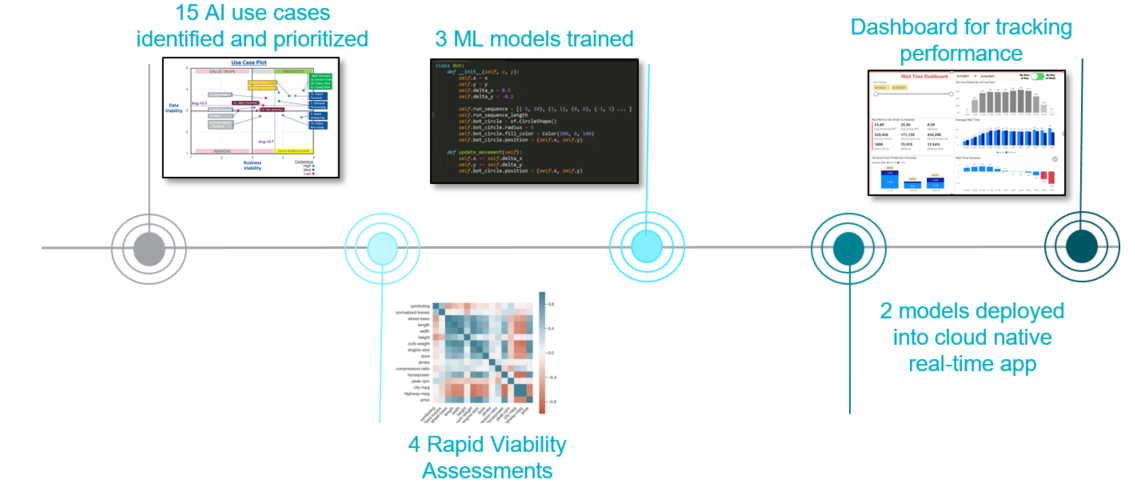
2. Fannie Mae’s Data Science Platform
One of the first sessions that I attended was Fannie Mae’s presentation on their data science platform. The focus was on how Fannie Mae overcame traditional data management challenges through innovative solutions. Data scientists at Fannie Mae were responsible for exploring internal and external datasets, including sensitive data to develop and train models, create reports and new datasets, deploy models, and share insights. Before the utilization of AI, Fannie Mae’s data scientists struggled with data access (mostly personally identifiable information), governance, and operationalization. In addition, underwriting analysts spent significant time extracting structured data from unstructured documents. On average, each analyst spent 5 hours on every document, with over 8,000 underwriting documents per year. The challenge of inefficient manual document analysis was also resolved by the utilization of AI.
By leveraging Large Language Models (LLMs) and ontologies, Fannie Mae developed a knowledge extraction system that significantly reduced manual effort. Tools like Amazon Bedrock, Claude 3 Sonnet, Amazon Neptune, LangChain, and Amazon OpenSearch Service played a crucial role in this transformation. The use of AI has generated a potential savings of over 32,000 hours annually and improvements in accuracy, compliance, and scalability of underwriting analysis for Fannie Mae.
Such efficiency and savings generated by the use of LLMs and ontologies is simply fascinating. This is a great reflection on how companies of all sectors can utilize the diverse capabilities of AI and customizable machine learning models to generate value.
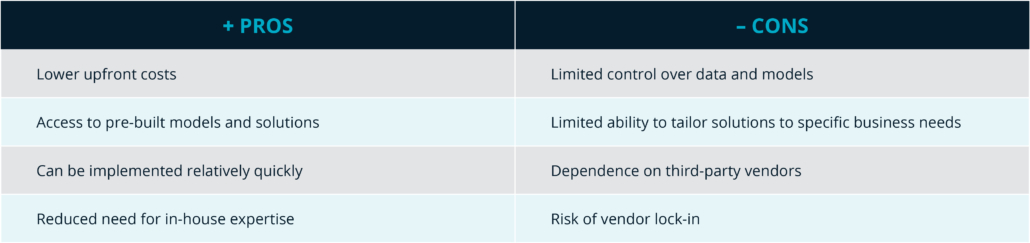
3. IBM WatsonX & AWS: Scale Gen AI Impact with Trusted Data
Generative AI was a major theme at the Summit, and IBM WatsonX and AWS highlighted their collaborative efforts to expand the impact of this technology. The WatsonX suite offers tools like Watsonx.ai for model development, Watsonx.data for scaling AI workloads, and Watsonx.governance for ensuring responsible AI practices. This partnership brings a shift towards more open, targeted, and cost-effective generative AI solutions, while offering superior price-performance at less than 60% of the traditional costs.
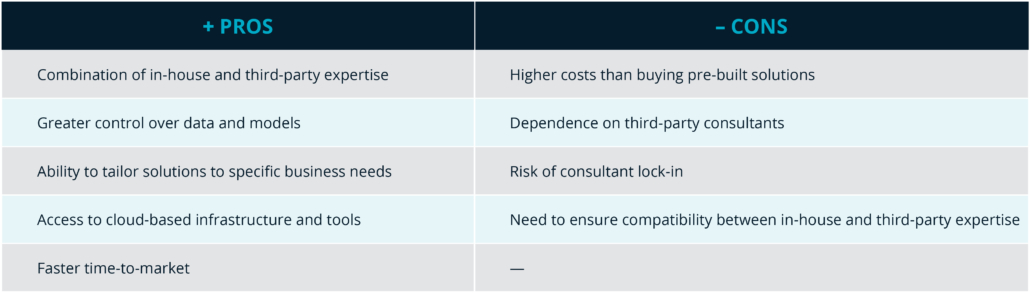
4. Advancing AI and Cloud Solutions
Another key topic of the Summit was Innovating with Generative AI on AWS. This topic highlights how businesses can focus on performance, cost-efficiency, and ethical responsibilities in AI development. Many strategies were discussed for creating new customer experiences, boosting productivity, and optimizing business processes through generative AI.
Some of the key techniques included Retrieval Augmented Generation (RAG) for combining new and existing information, fine-tuning of AI models, and pre-training to enhance AI capabilities. The session emphasized the importance of accessible and high-quality data as the foundation for AI success, so that businesses can utilize generative AI to its maximum potential to drive innovation and create value. By using services designed to enable innovation and scale, businesses are able to measure and track value and ROI while optimizing for cost, latency, and accuracy needs. In addition, businesses can manage risk, maintain trust, and build with compliance and governance.
5. Boosting Employee Productivity with AI Agents
Another highlight was the exploration of AI agents powered by Amazon Q. With Amazon Q, businesses can design these AI agents to integrate seamlessly with tools like Slack, Microsoft Teams, and other AWS-supported data sources to enhance employee productivity. These AI agents can improve efficiency across teams and organizations by streamlining data interactions and automating repetitive tasks. A demo of how to connect the Slack instance to Amazon Q and deploy it into the Slack workspace showed the simplicity of the whole process and how quick Amazon Q can generate value for an organization.
6. Building a Strong Data Foundation for Generative AI
A central theme at the Summit was the importance of a solid data foundation for successful generative AI initiatives. AWS demonstrated how businesses can harness structured and unstructured data through various tools and services. Key components of this foundation include:
- Data Storage: Managing structured and unstructured data using SQL, NoSQL, and graph databases
- Data Analytics: Utilizing data lakes for search, streaming, and interactive analytics
- Vector Embeddings: Tokenizing and storing data for semantic similarity searches
- Data Integration: Combining data from different sources using tools like AWS Glue and Amazon DataZone.
7. Governance and Compliance in the Cloud
Governance and compliance were also significant topics, with AWS highlighting how organizations can manage data securely and efficiently. Enterprise customers look for democratized data tools with built-in governance to discover, understand, and access data across organizations, with the ability for multiple personas to collaborate on the same data problems. In addition, easy-to-use and easy-to-access analytics and BI tools are crucial for value creation. The Summit showcased services like AWS IAM, Amazon Cognito, AWS Lake Formation, and Amazon S3 for data management, access control, and auditing. These tools help ensure that cloud operations are compliant with regulations and best practices
8. The Future of Generative AI
Lastly, the Summit concluded with a discussion on the future of generative AI. The evolution of AI agents such as Ninjatech.AI, multimodal models, and new regulations were some of the topics that were discussed. The session also explored the balance between value and feasibility in AI projects. It is crucial to identify the value generated from productivity, experience, and revenue, but also focus on the need for innovation that is both effective and sustainable.
The AWS Summit New York 2024 highlighted the latest advancements in cloud technology and AI. One of the major releases, Amazon Bedrock, allows businesses to build, deploy, and scale AI-driven solutions without extensive expertise and effort. This promotes businesses to focus more on performance, cost, and ethical responsibilities with gen AI.
The Summit offered valuable insights and tools for businesses looking to leverage cloud computing for innovation and efficiency. Many case studies were showcased to further support the adoption of generative AI in businesses of all sectors and instances where generative AI can create value for all aspects of the business. The sense of urgency to adopt gen AI has doubled since last year, and the emphasis to build a solid data foundation for successful generative AI initiatives has never been greater. The many new innovations simplifies the process for businesses to leverage data to create and differentiate generative AI applications, and create new value for customers and the business. The phrase “Your data is the differentiator” should be remembered as businesses navigate through the AI journey.
Overall, the AWS Summit provided a comprehensive look at how AWS is shaping the future of technology. With a strong emphasis on AI and machine learning advancements, security enhancements, and sustainability efforts, the future has never looked so bright for businesses, developers, and consumers.