The Newbie Data Science Guide: Beginning Advanced Analytics

Many of you have heard buzzwords such as “data science,” “big data,” or the “Internet of Things” before. You’re able to piece together that these fields relate to each other and deal with analyzing data in some way, but maybe you’re not so sure what these terms really mean. That’s what I’m here to help with. As a newer member of the data science field, I developed this short data science guide based on my experiences and perspectives in an effort to help those who are just starting out.
What Is Data Science?
The term data science has existed for many years but only in recent years has it been dubbed by Harvard Business Review to be “The Sexiest Job of the 21st Century” .
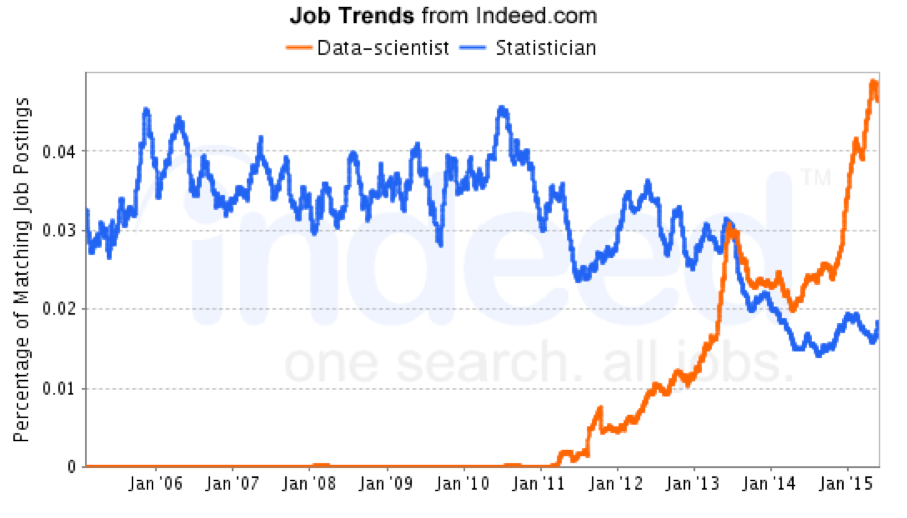
There is a lot of debate around exactly what this term means. Most can agree that, quite simply, data science is the study of data to generate insights. It lies at the intersection of computer science, statistics, predictive modeling, and business. It is often quite challenging to find an individual who is an expert in all sectors of data science, so corporations will often build a team of data scientists to balance out the talent.
Many argue that “data scientist” is simply a new, glorified term for a statistician or an analyst. Statisticians and business analysts have been around for decades, and their roles should not be discounted. While it’s true there’s a connection between these roles, it’s also a fact that the world is now producing data at an unparalleled speed. Everything now generates data: our smart phones, our cars, even our toasters. Forbes magazine estimated that by the year 2020, “1.7 megabytes of new information will be created every second for every human on the planet.” That’s a lot of data. To look at it another way, we currently perform approximately “40,000 queries each second on Google.” This equates to “1.2 trillion searches per year” . Data scientists are ideally placed to capitalize on these trends.
The Big Data Connection
Big data is usually defined as large amounts of data generated at high speed, usually in non-traditional or unstructured formats (such as Google Search queries). We now have access to data that never before existed. Location tracking applications like Foursquare and Google Maps are providing us with a new view of traffic patterns. Applications such as Twitter and Instagram are generating data on brand marketing. Fitbit, Polar, and Jawbone are generating personalized health tracking data. The ability of our devices to collect and generate data is what people in analytics call the Internet of Things.
The drastic increase in data collection has also driven the development of more powerful and user-friendly analytic tool sets. Tableau (and other competitors) have revolutionized data visualization by hiding the complex coding behind the scenes and presenting the user with a beautiful and easy to use drag-and-drop interface. Now, individuals at all levels can perform ad-hoc analysis on their data sets and they do not have to wait for an expert programmer to arrive. Additionally, companies such as IBM and SAS are incorporating more advanced algorithms into their analytic platforms, making it much easier for the end user to apply these methods without having to understand the intricacies of programming algorithmic code.
It probably goes without saying that an increase in data goes hand-in-hand with a need for increased data storage. You have likely noticed that cloud storage platforms are becoming more common. Additionally, computing power is also increasing an unparalleled rate. Personal computers are becoming more powerful, but more importantly distributed computing is becoming more efficient and accessible to analytics professionals. These technologies are changing the options organizations have for accessing massive amounts of useful information in a variety of ways:
- Crunching web logs to add them into a wider analytics strategy
- Deploying an open source distributed computing system for general processing of many data formats
- Assisting in the data preparation process for machine learning
- Many, many more applications
What Does a Data Scientist Do?
Forbes’s article points out that “at the moment less than 0.5% of all data is ever analyzed and used, just imagine the potential here” . This is where a data scientist can truly come into play. We have already established that there is a lot of new data. However, we must also consider that the vast majority of this new rapid data collection is messy and unstructured. Thousands of tweets are generated every second, and how many of them have typos or use slang terms or acronyms? How can we possibly ensure that we’re using this data properly?
Data scientists are trained to deal with messy, unstructured data. They understand how to write complex algorithms and code that can take data out of its messy form and structure it. These results may then be turned into a predictive model, an optimization equation, or a set of clusters, such as market segments, grouping them in specific categories.
Competitive Advantage
You might be thinking to yourself, “This all sounds great, but it doesn’t really apply to my industry or my company.” I challenge you to rethink your opinion. The rapid amount of data that we are collecting, as well as the improved computing power that’s now generally available, allows us to uncover facts about the world that we previously were unable to find. Blockbuster stood tall as a profitable video store before Netflix came along and used data to generate movie and TV show recommendation engines that are far superior to what a human behind a desk at Blockbuster could come up with. The taxi cab business was booming before Uber swept in and began hammering away at a huge chunk of the market share, connecting riders to drivers in the immediate area so neither party has a long wait.
These disruptive (and billion dollar) companies are fueled by data science. Data science lets companies use their data to drive these kinds of disruptive changes. Netflix optimized their recommendation engine. Uber is optimizing transportation routes and transportation cost by matching riders with nearby drivers. We all know that Facebook has become the social network, optimizing and revolutionizing how people connect all over the world.
These types of innovations are happening everywhere, in every industry imaginable. Data scientists are working with algorithms and predictive models toward the goal of personalized medicine, where an individual’s treatment plan is based on their unique genes and is no longer generalized for a disease. Marketing companies are getting smarter about advertising, and higher ed institutions are doing the same for fundraising. You probably notice that when you search for something online, all of the ads on your screen will suddenly start mimicking what you searched for. This is personalized marketing based on a predictive algorithm. Companies are sending you exactly what they think you are looking for in real time. The power of this is fascinating.
How Do I Get Started?
I started my professional career as a chemical engineer. I always had an interest in math and science and chose a profession where I knew the two would intersect. In my first job out of college, I found that I was drawn to problems that required data and analytics to solve. I was fascinated by how statistical analysis could yield predictions of when the next major breakdown of a machine might occur, or how the use of optimization algorithms assisted with supply chain logistics and shift scheduling. I was also fascinated with the way that data was structured, captured, cleaned, manipulated, and finally brought together for analysis.
Data science requires a constant curiosity about the world, a strong understanding of statistics, an ability to program, and business acumen. I found that, while I was tenacious and curious, I was lacking a formal background in these topics and decided to return to school to pursue my Master’s of Science in Business Analytics with a focus in Data Science. For me, the goal was a rapid career shift. I felt so passionate about analytics that I wanted to do a deep dive right into the information so that I could quickly insert myself back into industry to continue learning.
Grad School or Self-Paced Training
While returning to graduate school is a fantastic option for those looking to deep dive into the field and rapidly switch careers, this is not always a feasible or appropriate path. We live in an age where Massive Online Open Courses (MOOC) are on the rise. Driven individuals can take courses on services such as Coursera, Udemy, and EDX for little to no cost. These websites have classes in basic statistics, introductory data science courses, and programming language instruction in every discipline. I highly recommend checking it out even if you are considering pursuing a graduate degree. It never hurts to test the waters with a free course to ensure the material is interesting to you.
Statistics and Programming
If you have never taken a statistics course or are fuzzy on the fundamentals, start with that. It is critical that you have a strong baseline understanding of probability and statistics prior to moving forward. Once you have a baseline established, the next step will be to choose a programming language to learn and stick with it. Most corporations agree that knowing one language well is better than knowing just a little bit of several languages.
The most widely used languages in data science are Python and R, as they are open source (free to use). To determine what language will be best for you to learn, I suggest you read job descriptions of what data scientists do in a variety of industries. Find job descriptions that sound interesting to you. Assemble of list of skills you will need to learn and develop a path to learn them. Don’t try to learn everything at once. Focus on one topic at a time and build to the next one.
Reading and Practice
The data science field is massive and continuing to grow. To get the most of your career change, I highly recommend that you immerse yourself as deeply as possible. Read blog posts such as KDNuggets or FiveThirtyEight (there are hundreds more), subscribe to data science podcasts (my favorite is Partially Derivative), and follow data scientists and data science companies on LinkedIn. Do not be intimidated if everything you read or hear doesn’t make sense at first. Slowly but surely the dots will start to connect, and this connection will occur faster the more you immerse yourself in the data science world!
Once you start to get the basics down, practice, practice, practice! Often, employers will ask to see a sample of code or a project you have worked on. If you have trouble coming up with a unique idea, participate in a Kaggle competition or download open source data sets and play around. Be prepared to put in a lot of hard work, but also know that if you are truly interested and passionate about the field all of your efforts will be rewarded.
Ironside Data Science
It never hurts to have expert help. Here at Ironside we have both an Analytics Advisory team that helps organizations shape their business strategy for data management and a Data Science & Advanced Analytics team that effectively implements powerful data science solutions for clients. During a data science engagement, our team will mentor you directly, working side by side with you to get you up to speed with key data science concepts and tools. If you found this data science guide useful and see an opportunity at your organization, we’d love to talk with you.


