Why to Use Spark for Data Prep and Machine Learning

The immense amount of data being collected today, in any industry, expands the reality of advanced analytics and data science. In concept, it creates an explosion of opportunities and expands what can be accomplished. In reality, we are often limited in scope by our data processing systems which may not be able to handle the complexity and quantity of data available to us. The introduction of Spark has offered a solution to this issue with a cluster computing platform that outperforms Hadoop. Its Resilient Distributed Dataset (RDD) allows for parallel processing on a distributed collection of objects enhancing the speed of data processing. For this reason, Spark has received a lot of interest and promotion in the world of big data and advanced analytics, and for good reason.
Today, I’ll talk about the benefits of Spark specifically for the tasks of data preparation and machine learning. I’ll be focusing on the role of a data scientist as opposed to a data engineer, who is also likely to find extensive value in Spark, but the benefits outlined here will apply to both. Although there are now many paid and open source tools on the market for data preparation and machine learning, Spark may be the ideal solution for your data science needs. Let’s take a look at the features that make Spark so appealing and support all the hype.
1. It’s Fast
Spark was designed to overcome the shortcomings of Hadoop MapReduce, and boy did it succeed. Unlike Hadoop, it has the ability to cache results periodically in-memory which allows for faster processing. It’s estimated to be 100 times faster in-memory or 10 times faster on disk compared to Hadoop MapReduce. Consider the example of Toyota Motor Sales. They succeeded in shortening processing time of one massive job from 160 hours to just 4 hours by re-writing the job to run in Spark! If you’re working with big data, especially if real-time processing is a priority for you, Spark is an obvious choice.
2. It’s Efficient
Spark eliminates the need for multiple systems within an organization. It addresses several critical needs through a single system, including data manipulation, modeling, testing, streaming, batch or single jobs, queries, and maintenance. Managing all these tasks from a single system saves on overhead and allows smoother collaboration and integration across your environment and different business functions.
3. It Opens You Up to a Wider Talent Pool
As with any tool, you need to find the right person to execute jobs, which can be difficult when the tool requires a very specific skill. Spark avoids this to a degree by offering the ability to write jobs in multiple programming languages. Any data scientist with some programming knowledge of Java, Python, SQL, or Scala can work in Spark. This makes finding the right talent easier and opens doors for multiple users.
4. It’s Vendor Agnostic
Spark is an open source tool that can work with multiple platforms and doesn’t care which one you use, so if you change Hadoop vendors or move away from a Hadoop system entirely, it won’t disrupt your Spark-based infrastructure. You can also run Spark itself in a variety of platforms. For example, Databricks is an excellent option that allows jobs and scripts to be organized into notebooks and notated. Notebooks offer an integrated workspace for development, collaboration, and visualization.
Spark’s Architecture
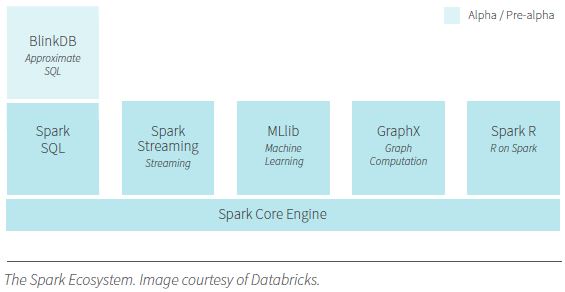
Let’s step back and look at the architecture of Spark for a moment. Originally, Spark was designed to replace Hadoop MapReduce and offer faster processing. Over time, additionally libraries have been created that sit on top of the Spark Core API and include Spark SQL, Spark streaming, MLlib, and GraphX. One of the benefits of this structure is that all libraries are optimized when changes are made to the Core API. Spark SQL and Spark streaming support querying and real-time processing. MLlib is a machine learning library that provides a vast array of algorithms, including those for classification, regression, clustering, collaborative filtering, and dimensionality reduction. GraphX is an extensive graphing library that can also be used for social network analysis and natural language processing. With this combination of libraries, Spark has become a fully functioning tool for data scientists that allows data preparation, machine learning, and visualization all in one instrument. As part of the Apache open source community, Spark and its libraries are constantly being updated and improved. New algorithms and functions are being added all the time.
The Bottom Line
With all the new technologies out there, it can be hard to keep up. But the general consensus in the field is that Spark is a major player in big data and advanced analytics and is more likely to expand than to be replaced any time soon.
Of course, Spark is only one piece in the larger puzzle of big data and advanced analytics. If you’d like to know more about some of the other key technologies and theories in the space, check out these other related resources:
- Diving into the Data Lake with Hadoop
- Hadoop Ecosystem Quick Start: 5 Key Components
- Beyond Market Basket Analysis: Extending Association Rules
- Ironside Data Scientist Interviews
- Ironside Data Science & Advanced Analytics Team Page


