Do You Have a Big Data Problem?

By now, we’ve all heard the V3 definition for Big Data maybe a million times: Volume (Size of Data), Variety (Type of Data) and Velocity (Frequency of Data) with Veracity (Accuracy of Derived Insights) thrown in as an extra sometimes. The issue is that this all-too-common definition has caused some confusion in organizations around who qualifies as having big data or a big data problem.
Some of the misconceptions that lead organizations to think they don’t have a big data problem are listed below:
* We don’t have huge volumes of data.
* We only deal with structured data.
* We don’t have the need for real-time data and only do batch processing.
So that said, how do you know when you actually have a big data problem? It boils down to one simple fact:
“If you can’t handle all your data with existing capabilities, you have A BIG DATA PROBLEM.”
Most organizations today would like to leverage various types of information, including structured, unstructured, or semi-structured sources. In fact, 80-90% of most data these days is unstructured, so handling it is becoming a bigger and bigger priority. As a result of these trend shifts, many companies have more data than they can (or want to) handle with traditional technical infrastructures and can’t leverage most of it due to their need to first format this data (build ETL processes) to fit into an existing schema-bound target, such as a data mart or data warehouse.
Also, not all the data that flows into an organization’s system is actual intelligence that provides actionable insights and business value. Instead, a lot of it could very well be noise that they should ignore. Many organizations use this fact as a rationale for not wanting to go through the entire project life cycle required to get all this data into their existing analytical ecosystem. After all, if there’s the potential to get no ROI on the time, money, and effort spent by both the business and IT teams, why do it, right?
Despite this argument, however, the majority of organizations need to solve their big data problem even if they don’t realize it yet. Here are a few steps we all should take:
- Craft new technical architectures that have the flexibility to handle all types of data and can upscale/downscale (add/remove nodes from the cluster) as needed without IT having to provision the environment every time business users want to analyze a new source of big data.
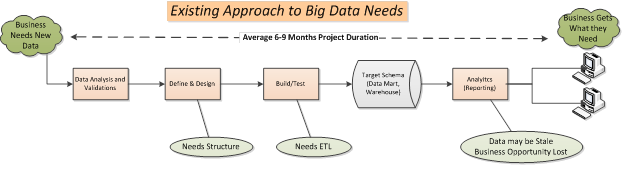
- Build analytics sandboxes, which enable high performance analyses using in-database/in-memory processing capabilities. This approach reduces the cost and risk coming from business users trying data replication by utilizing “shadow” file systems – local data marts that don’t have any security/governance around them (siloed analytics). Sandboxes allow all experimentation to come from a single source of verified data without compromising the production environment. This helps data discovery be analyst owned rather than DBA owned as it is in most current architectures, as the diagram below shows.
Now that we understand that a big data project is necessary and know what we need to get going, we should consider two other commonly used terms these days – data science teams and data lakes.
* Data science teams should ideally consist of the following people:
* Business Sponsors
* Data Engineers
* DBAs
* Line of Business Users
* Analysts
* Data Scientists
The data science team’s main goal is to generate diverse ideas, help the organization understand their data better, and define the future foundation for analytics in the organization. While we’re familiar with most of the positions listed above, the data scientist role is a relatively new phenomenon.
So what is a data scientist? Put simply, it’s a person who combines business acumen with analytical creativity and technical expertise. These people are good at more than just math and statistics! They can truly give you the keys to your organization’s future, letting you establish the trends instead of following them.
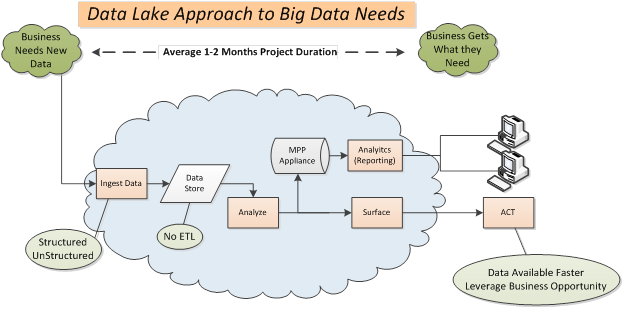
A data lake is a single cohesive engine that enables seamless data provisioning and usage of source/analytics and visualization tools. As we mentioned recently in a more in-depth article on the subject, data lakes store every size, type, and format of data.
They enable us to analyze anything using merged/full/parts of data sets with a very quick time to market. Using this approach, very little time is needed for the big data project to get up and running, unlike the average 6-9 month lead time for similar traditional data projects. With the right proven practices informing its governance, a data lake can be a huge asset to your big data solution.
We only briefly covered these two important and huge topics in this article, but for further details look for more upcoming articles in the big data space and read up on the topics we’ve already covered. If you have questions or want to start addressing your big data problem, please feel free to contact us. We’d be glad to help you evolve your infrastructure.


