Dynamic Query Mode for Relational Databases
In September, IBM introduced Cognos version 10.1.1, the latest update to Cognos 10. Among the significant enhancements in the software is the ability to Dynamic Query Mode with relational databases.
Dynamic Query Mode (DQM) is an intelligent data caching mechanism which can dramatically improve the performance of OLAP style queries. With the prior version, DQM supported cubes built from TM1, Essbase and SAP BW. With version 10.1.1, IBM Cognos adds support for Microsoft SQL Server Analysis cubes, and the most common relational databases, specifically DB2, Netezza, SQL Server, Teradata and Oracle.
Prior to DQM, cube base queries, issuing MDX code, could suffer from poor, or uneven performance. This was especially noticeable in cases where suppression, such as null suppression, was turned on. DQM produces a sharable data caches, including plan caches, and also optimizes database queries. This resulting in quicker, more even queries, particularly noticeable in an ad-hoc query environment. It also retains user-based security restrictions.
DQM over relational data sources is only supported for Dynamically Modeled Relational (DMR) packages. Package not published with DQM turned on, will execute in the traditional manner, which is now called Compatibility Mode, to distinguish it from Dynamic Query Mode.
Dynamic Query Mode introduces the concept of a memory-resident data cache. Unlike Compatibility Mode, reports and queries will produce only MDX code (as opposed to SQL code), and only against the data cache. The query engine may ultimately issue SQL code against the database in order to populate the cache. However the code you will see by examining the report will show only MDX code. The data engine may satisfy queries by returning data from both the existing cache and from new database queries, if some data does not already exist in the cache. But this is invisible to the specific report. The result is that minimal and simplified queries are issued against the database, and only when the data does not exist in the cache (subject to security rules).
In order to enable DQM there are a few specific steps.
- DQM requires JDBC drivers for relational data sources and required database clients for any OLAP data sources. The JDBC drivers must be copied to the Cognos environment. See the IBM Cognos Administration and Security Guide for details. You may need to restart the IBM Cognos services after installing the drivers.
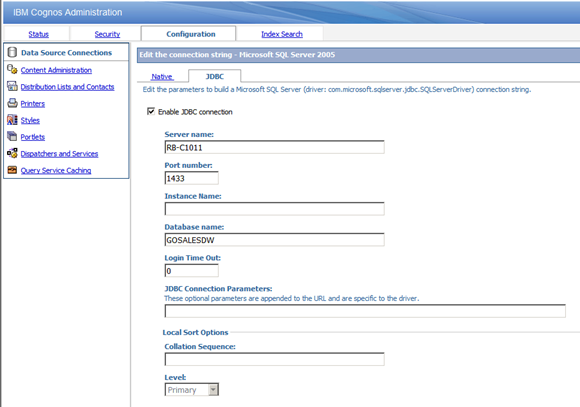
- For the Relational data sources, you must enable the JDBC data connection. In the data connection configuration, select
Enable JDBC Connection as shown.
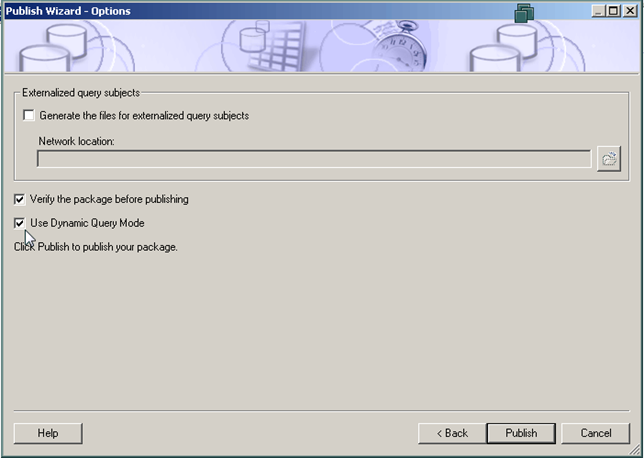
- In Framework manager, when you publish the package, select the checkbox indicating Dynamic Query Mode, as shown. This enables DQM for that package.
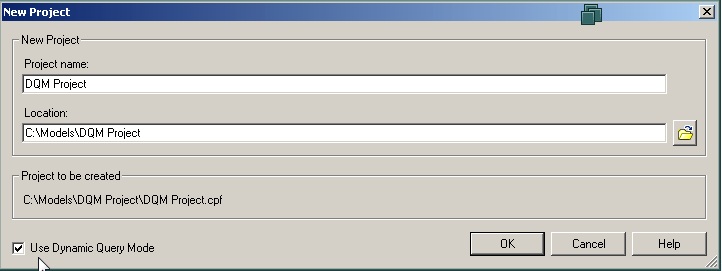
As another option, when starting a new Framework Manager project which will be used only with DQM enabled data sources, you can enable the entire project to use DQM, as shown. All testing and publishing will use DQM by default.
Testing and Monitoring
IBM Cognos Lifecycle Manager is a great tool for comparing report results with and without DQM. In addition to highlighting any potential differences, it can also compare execution times
IBM provides a free tool IBM Cognos Dynamic Query Analyzer to help diagnose potential issues with the queries. It displays a graphical representation of the queries generated when running a report. You can also run reports from within Dynamic Query Analyzer. See the Dynamic Query Cookbook (IBM Website)
for more information.
Modeling Challenges
In order to utilize DQM, the Framework Manager model must be carefully modeled according to proven practices. For example, modeling many-to-many relationships is never recommended, but will produce errors when used in a DQM package.
Conclusions
Dynamic Query Mode over relational data sources has the potential to be a game-changer. There are certainly some challenges, which are only touched on here. But in the right environment, there is the potential for huge performance gains.
What is the right environment? While it’s difficult to give hard-and-fast rules, I would look for a well-designed dimensional data warehouse as a data source. This lends itself to DMR style data modeling and reports. Also, what is the data refresh cycle? Frequently updated data will benefit less from data caching than data which is more static in nature. Also the number and type of queries issues is a consideration. Are there a large number of ad-hoc, analysis style queries? Repeated analysis is more likely to see benefits than simply running canned reports on a periodic basis.