Five Essential Capabilities: Elastic Data Processing & Storage

This is part five in our five part series on the essential capabilities of the competitive data-driven enterprise.
Over the last 20 years of doing business we have seen a number of different analytical data storage and query concepts fall in and out of favor. Throughout this time, a wave of digital transformation in business has dramatically increased the volume of collected data. Machine learning and other probabilistic methods benefit greatly from the law of large numbers so if by now it wasn’t already clear, all that talk about “big data” has really been about the analytics that it enables. As a result, today’s knowledge workers are predisposed to data hoarding, preferring to save everything including the data for which there are no known use cases, since its future value to the organization may still yet be discovered.
We have intentionally avoided describing this capability as either a data lake or a data warehouse, as we have observed that both these terms are highly subjective and can carry vastly different connotations from business to business. This concept is less about how you choose to model the data, and more about how elasticity (often characterized as “the cloud”) fundamentally changes the economics of data storage and processing in ways that will reduce the time and cost to solve familiar problems, as well as dramatically lower the risks associated with experimentation and innovation. Let’s explore the key elements of data processing and storage elasticity that make it such a valuable capability for the competitive data-driven enterprise.
Separate Storage and Compute
Traditional relational database management systems (RDBMS) and warehouse appliances conflate the concepts of data storage and data processing power. If you wish to store more data, you must also purchase additional processing capacity, and because these platforms cannot be dynamically scaled you must make these purchases in larger stepwise increments (i.e. software licenses, blades, or racks) that will almost certainly remain an underutilized asset. Modern analytical data processing technologies such as Snowflake, Amazon Athena, Hadoop and Spark are designed with separate storage and compute in mind. These new models allow for you to keep your data in some form of object storage such as Amazon S3 or HDFS, and query or process it where it sits using a wide variety of fit-for-purpose engines. With this key point of differentiation from traditional RDBMS, platform owners can lower their cost of query-able storage from quoted highs of around $10,000 per year/terabyte for an appliance to as little as $40 on an elastic platform.
Massive Parallelism and Dynamic Scaling
Modern analytic data platforms are designed with parallelism in mind, and allow the platform owner or analyst to dynamically increase or decrease the number of resources they have available which in turn can speed up queries, and reduce the time (and additional hardware and software) required for both data transformation tasks and machine learning model training. A native parallel architecture also allows these systems to scale up or down seamlessly without the costly data replication and clunky overhead of classic “database clustering” paradigms.
Business Agility & Innovation
Again, pay-per-use models prevail that can be leveraged to manage expenses, and also encourage data experimentation and innovation. For example, a project team could quickly provision an Amazon Elastic Mapreduce (EMR) cluster to perform an experimental data processing job atop data already stored in Amazon S3. If the results of the experiment are unfavorable, that team would only be tens, hundreds or thousands of dollars out of pocket and the knowledge of the experience would inform the next round of innovation. In a traditional on-premise environment, that experiment of unknown business value might have necessitated a seven figure infrastructure and personnel outlay, which more than likely means it never would have been attempted.
Elastic Data Processing & Storage Essentials
Organizations that recognize these clear advantages and begin to shift their analytic query, data processing and storage to elastic platforms will be the first to reap the corresponding business benefits. When considering how you implement this capability as part of your architecture there are a few key features you should consider:
- Support for loading and querying from separate object storage on popular platforms such as Amazon S3, HDFS or Azure Data Lake Store
- Self-tuning and optimizing architectures the minimize the need for administrative resources and customized indexing
- Support for document-based data formats such as JSON
- Provides a high performance, high concurrency SQL interface with support for Native, JDBC and/or ODBC APIs
- Fast and easy software-defined instance provisioning and administration through an intuitive management UI
- Support for seamless parallelism and pay-per-use compute scaling in micro-increments
- Deployable as an on-demand service without the need for a large internal IT infrastructure and administrative outlay
Bringing it All Together
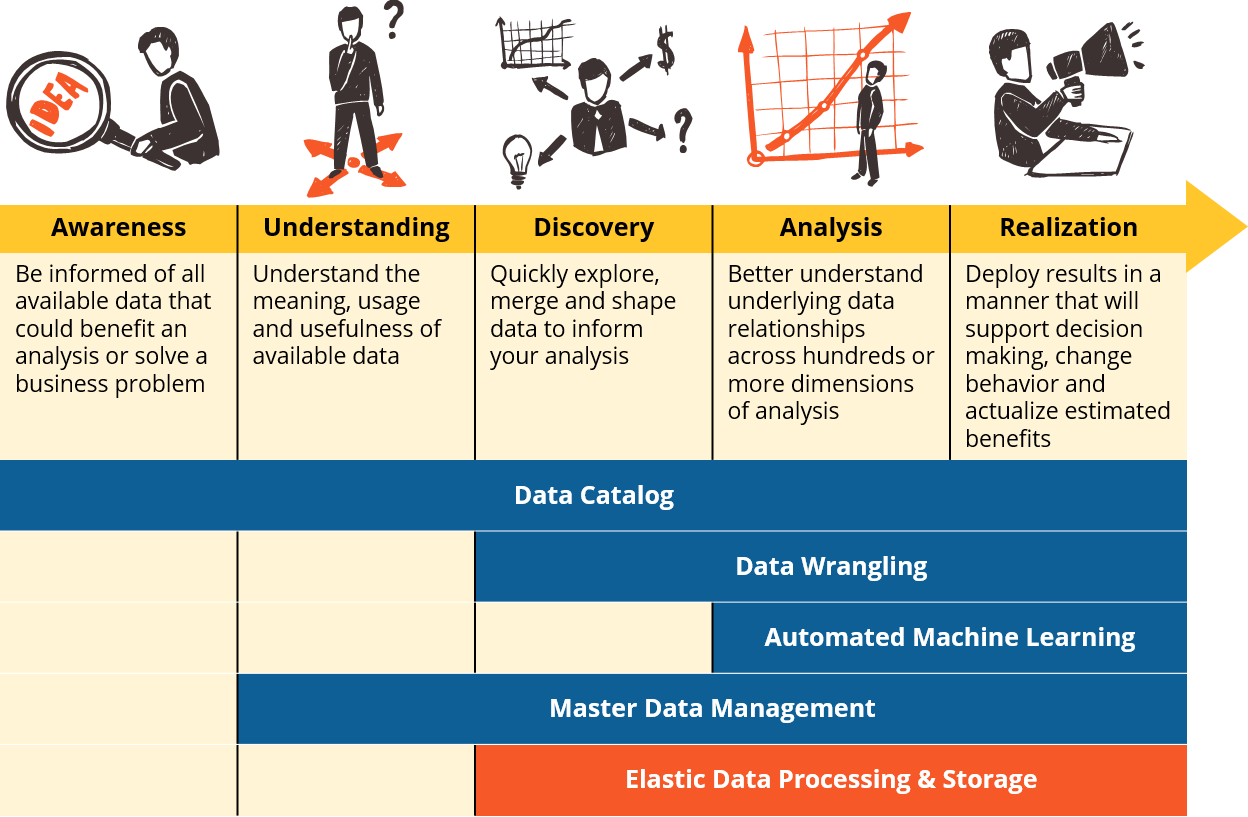
Together these five capabilities (as well as other established methods such as data visualization) come together to streamline and democratize the process of data analysis, so that more individuals in your organization can participate in data-driven problem solving, and do so with greater efficiency and accuracy than before. We believe that deploying this citizen analyst workbench in combination with a pragmatic, value-driven approach to data governance is how the modern business will cultivate a data-driven culture, enable lean business analytics, develop their analytic skills and talent faster, and become highly competitive in the face near constant market change and disruption.

A high level representation of the citizen analyst workbench, along with exemplary technology vendors that were discussed during our series.
About Ironside
Ironside was founded in 1999 as an enterprise data and analytics solution provider and system integrator. Our clients hire us to acquire, enrich and measure their data so they can make smarter, better decisions about their business. No matter your industry or specific business challenges, Ironside has the experience, perspective and agility to help transform your analytic environment.

